3 Platform Engineering Shifts From Devoxx France 2026
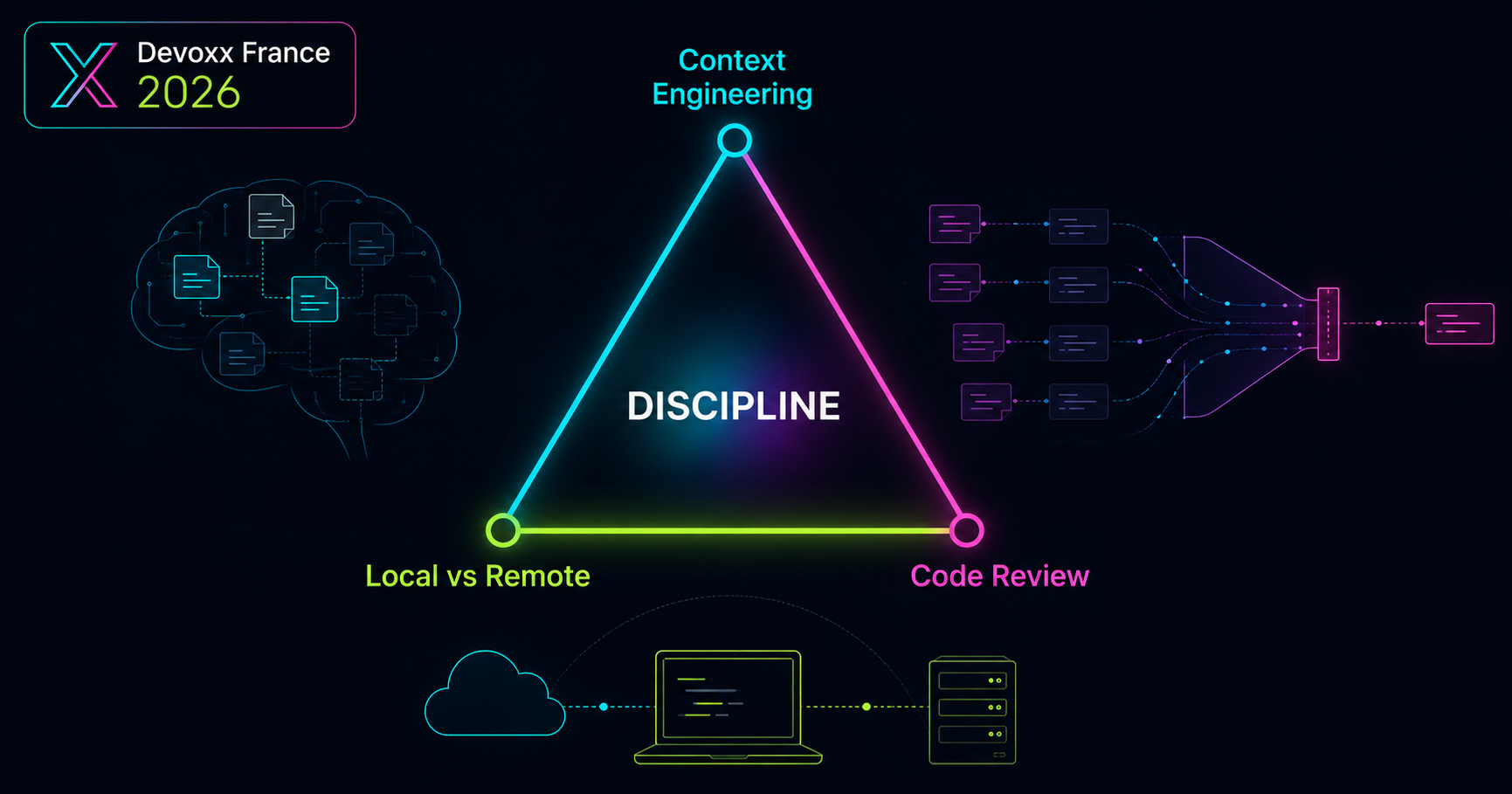
Three days, 20 talks at Devoxx France 2026. The through-line wasn't AI hype - it was discipline. Context engineering, code review under AI volume, and the local-vs-remote question now shaping security, cost, and sovereignty.
Context is the new system prompt. Frontier LLMs lose 63 points of accuracy between fixing known bugs and implementing features - because they don't know what your team knows. Harness engineering (context files, evaluation, governance, guardrails) is now a production artifact, designed and versioned like code.
Code review is the new bottleneck. AI-generated PRs are accepted at 32% versus 84% for humans. The cost of software moved from writing to everything after the commit. Smaller units of change, preview environments, and resilient CI/CD are no longer hygiene - they're survival.
Local or remote runs through your whole stack. Where the agent runs and where the model runs are now security, cost, and sovereignty questions. Sandboxed agents and on-premise SLMs are becoming the default architectural assumption.
I headed to Paris for Devoxx France 2026 with a list of must-see topics: generative AI, Java, Quarkus vs Spring Boot. But three days and 20 talks later, a single through-line emerged instead: discipline.
Across every track, engineering discipline has reasserted itself across four distinct vectors: context engineering, change management, cost optimization, and sovereignty.
The talks I valued most all echoed the same sentiment: AI changed the stakes but it didn't change the fundamentals. We're no longer in the "growth at all costs" era. Profitability is a real constraint again, every euro spent has to justify itself. In that context, three operational truths emerged, unfolding in the exact order they hit a developer's daily workflow from the prompts you write to the infrastructure where your code actually runs.
Devoxx France 2026 - main stage (image source Devoxx France - Flickr)Devoxx France 2026 - main stage. (image source Devoxx France - Flickr)Devoxx France 2026 - DisciplineDevoxx France 2026 - Discipline
Truth 1: without harness engineering, your AI doesn't know what your team knows
A 63-point gap
Same model, different task. Benoit Fontaine opens his talk with a slide on frontier LLM performance: Claude Opus 4.5 scores at a solid 74% on SWBench (the benchmark for fixing real GitHub bugs on popular open-source repos). Then he flips to the next slide. Same model but on Feature Bench: same setup, same repos, but the task is implementing a new feature from a spec, not fixing a known bug. No stack trace. No failing tests.
The results? An 11% success rate. That's a 63-point gap.
SWBench vs Feature Bench - 63 point gap on the same Claude Opus 4.5 modelSame model, different task: SWBench 74% vs Feature Bench 11%.
The autopsy
The next thirty minutes, he shows why.
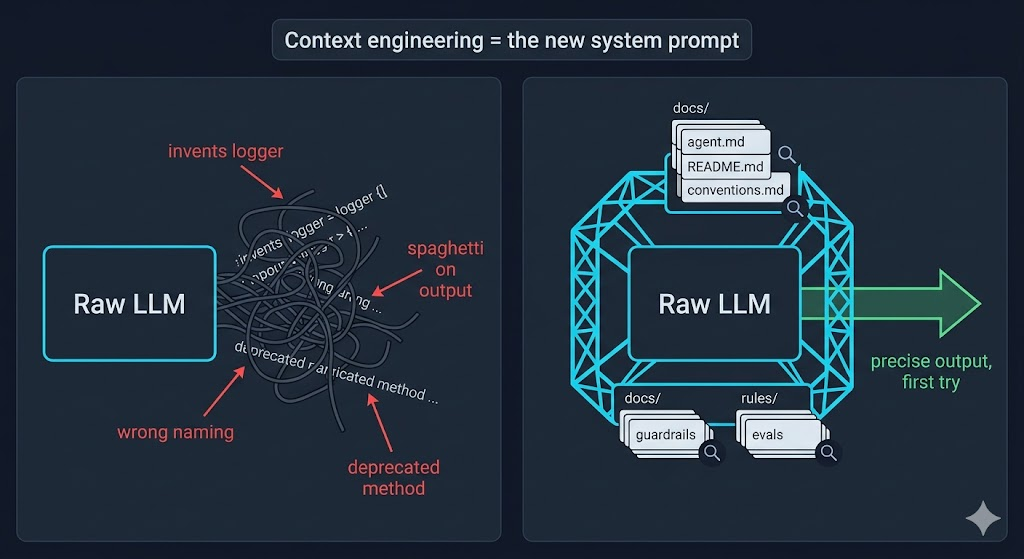
The model invents a logger that doesn't exist.
It picks a naming convention nobody on the team uses.
It calls a method deprecated three sprints ago.
In the end, 80% of the failures look like the same problem: the model didn't know what the developers knew.
Context rot
Context size matters too. He cites Stanford's "lost-in-the-middle" research: 30% accuracy loss in the middle of a long context. We call it context rot. Anthropic now recommends compacting at 60% utilization. Above 83.5%, the session is dead, auto-compaction triggers, and the agent forgets what it was doing two minutes ago.
Quality drops, and the bill follows: more tokens per request, more round-trips to recover from errors. A poorly managed context costs twice: in accuracy and in dollars. "And it's no longer free," he adds. Subsidized inference is ending. SOTA LLM providers change their pricing terms regularly, always pulling prices up.
The answer
To fix these problems, he opens an unusual real 108,000-line codebase which contains 26,000 lines of agent.md files and per-directory READMEs designed to be lazy-loaded by an agent - which represents 24% of the codebase.
According to him, this is how you correctly steer an LLM, with a much better result on the first try. With this technique, the model has access to a minimal context, lazy-loaded, yet very precise based on the directory where it has to work. Context engineering is "the new system prompt." It's the input of an AI in production.
A 108k-line codebase with 26k lines of agent.md files and per-directory READMEsLazy-loaded, per-directory context: 24% of the codebase is written for the agent.
Making it operational
Harness engineering. The term I kept hearing in the hallways was harness engineering. It's the scaffolding around the model: context files, evaluation, governance, guardrails.
Packmind. I had the same conversation with the Packmind team between two sessions. Their tagline - "the engineering playbook behind your AI code" - is a rewording of what Benoit was demonstrating, scaled to the whole company. Their platform captures an organization's standards (conventions, security rules, internal patterns) and distributes them to agents as versioned, governed context. Same logic: context treated as code artifacts, not as a prompt.
qovery-skills. This is exactly the principle applied in qovery-skills. Several Claude Code skills (/qovery-deploy, /qovery-troubleshoot, /qovery-optimize, /qovery-preview...), each with a small, tight, scoped piece of context that teaches an agent how to interact with our platform without dumping our entire docs into the context window. Same pattern Benoit was teaching: a small, lazy-loaded context beats a big, eager-loaded one on quality and on cost.
Context has become a production artifact you have to design, version, and ship the same way you do code. The same engineering discipline you apply to the rest of the stack. Without it, AI improvises: it invents conventions, accumulates useless context that drags down quality and ultimately inflates the bill. Teams ignoring harness engineering are already working slower and they just haven't measured it yet.
Truth 2: code review has become the bottleneck
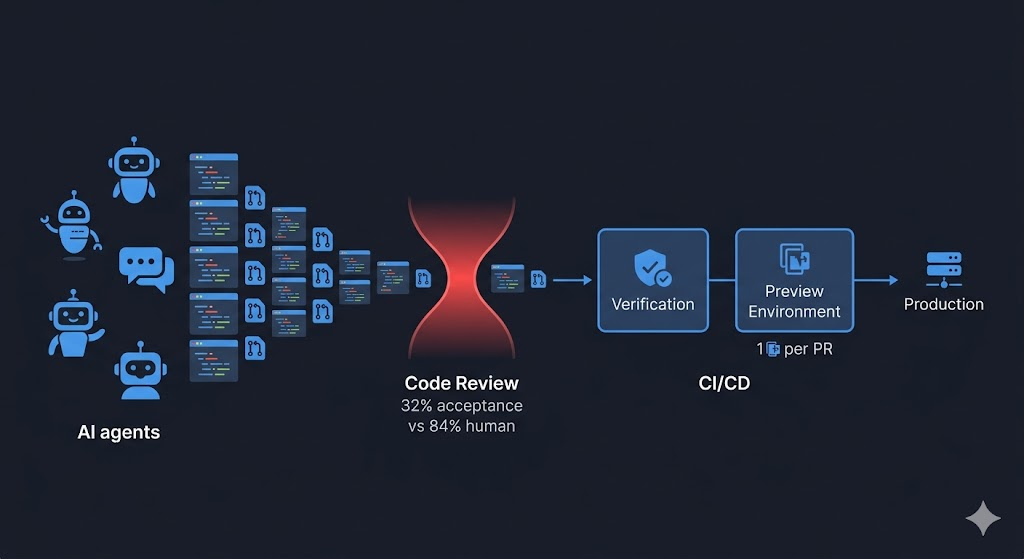
32% vs 84%
The development cost moved. With LLMs, we ship code faster, sometimes at higher quality. But the cost is no longer in the writing, it's in everything that comes after the commit: the CI/CD pipelines to run, the feature flags to validate, the deployments to coordinate. The problem now lives in the pipeline between commit and prod.
The numbers
Per the Opsera study, on 250,000 developers measured:
AI-generated PRs accepted: 32%.
Human PRs accepted: 84%.
AI accelerated the writing step and shoved the bottleneck into review. A parallel study by DX on 121,000 developers went further: AI acts as a universal amplifier, doubling incident rates in low-maturity organizations while halving them in mature ones.
Same tool, opposite outcomes. It all depends on whether your review and deployment pipelines are ready for volume.
The discipline that absorbs
Incremental migration. Hela Ben Khalfallah presented incremental migration strategies (Strangler Fig, Parallel Change, Branch by Abstraction), all sharing one common principle: every step must be deployable, reversible, observable. The discipline that scales when code volume explodes.
Defense in depth. Docaposte's CISO made the same demonstration on the security side. When Trivy itself was compromised in early 2026, their CI pipeline was running four scanners in parallel: Gitleaks, Semgrep, AquaTrivy, Checkov. They blocked the poisoned versions and kept shipping without changing a line of pipeline. It's the same property that protects you when PR volume doubles: a pipeline with no single point of failure keeps running, whether under a supply-chain attack or under a wave of AI-generated code.
The AI-generated Pull Request wavesThe AI-generated Pull Request waves
Smaller units
When AI doubles writing velocity, every friction after the commit becomes a cost multiplier.
Preview environments. The way out is smaller, more isolated, more deployable units of change. Per-pull-request preview environments (such as the ones Qovery provides) operationalize this principle: every PR clones a complete, ephemeral, disposable environment. Code review stops being a diff read. It becomes a visual, end-to-end validation on running code.
None of these disciplines (atomic commits, independent deploys, preview environments, resilient CI/CD) is new. What changes in 2026 isn't the practice, it's the pressure: what was good team hygiene a few years ago has become a survival condition. AI just made this bottleneck impossible to keep ignoring.
Run AI agents safely on infrastructure you control.
Qovery Remote Development Environments give your team isolated, governed workspaces with Claude Code, OpenCode, and Copilot pre-integrated - no SSH keys leaking to agents, no shadow inference bills.
Truth 3: local or remote - the question runs through your tooling, your security, and your AI
The problem: local agent, remote model
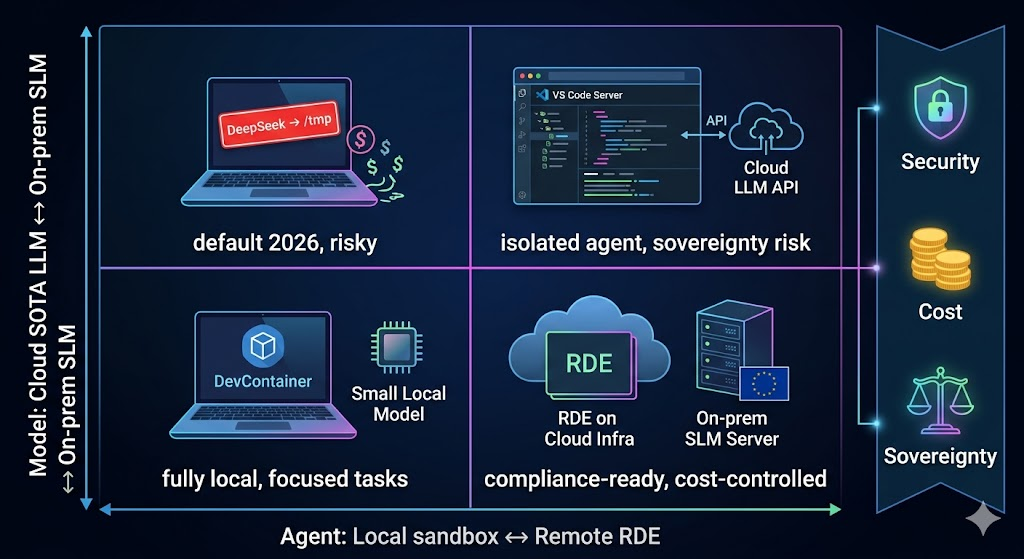
The default setup in 2026: a dev codes on their laptop, the AI agent runs in their terminal and calls a cloud LLM (Claude, ChatGPT, Gemini). Convenient. And risky on three axes at once.
Security. Thomas Rumas (Adeo) tells the story: "We started experimenting with LLM-assisted development." Then, deadpan: "DeepSeek connected to /tmp." The agent had wandered out of its working directory looking for source files. On a dev laptop with SSH keys and credentials. The MCP security talk laid out the numbers: 72% tool-poisoning success rate, 92% probability of multi-MCP cross-context exploit when servers share the same context window, 2,117 publicly exposed secrets in MCP repos. A real 2026 supply-chain attack: a Python package's tool description was modified post-review to exfiltrate SSH keys, undetected until the keys showed up in the wild.
Cost. These SOTA models carry a high per-token cost under normal usage, so during an excessive-consumption attack (a prompt injection that forces the LLM to re-call its tool in an infinite loop) it's a disaster. Five dollars per iteration. No circuit breaker, the bill writes itself.
Sovereignty. The EU AI Act has been in force since August 2024. High-risk AI requirements (for example in the finance domain) come into effect in August 2026. Docaposte already bans extraterritorial LLMs on confidential data; their CISO doesn't have to make that case anymore, the regulation does it for them. Sending proprietary code to a SOTA cloud LLM is now a compliance question.
The solution: isolate the agent, bring the model back
The way out runs through two independent but complementary decisions.
Isolate the agent. Move the agent into a sandbox (like a DevContainer or micro-VM), or a Remote Development Environment (RDE), a dev environment that runs on your infra, accessed from the laptop. The agent loses access to the developer's SSH keys, credentials, and host filesystem. This also gets rid of permission fatigue: instead of interrupting developers with a confirmation prompt every 30 seconds, sandboxing allows running the agent safely in "YOLO mode."
Bring the model back. For sensitive use cases, drop the SOTA cloud LLM and run an SLM on infrastructure you control. Pierre's SLM talk shows that small models, on focused tasks, are systematically better: Gemma 4, 20× smaller than the flagships, beats Anthropic on instruction following. Large models generate more side effects and more hallucinations on instruction-bound tasks.
Local sandboxed or remote dev environment. Cloud or on-prem model. The same question asked at two levels of your stack. In both cases, the answer shapes your security, your costs, and what you can actually run.
Industrialize
DevContainer for the local agent. The most visible industrialization. Thomas Rumas walks through the old onboarding, 30 pages of Confluence to prepare the environment: 3 to 5 days before the first line of code, multiplied by 1,500 to 2,000 developers across Leroy Merlin, Bricoman, and Webdoc. The DevContainer that replaced it: a checked-in devcontainer.json, a Dockerfile based on the Java image, features for project tooling. Open the repo in VS Code, 90 seconds later the environment is ready.
Docker Sandbox. The sandbox CLI runs agents (Claude, Gemini, Codex, Copilot) inside isolated micro-VMs with their own Docker daemon and their own network rules. Credentials never leave the host, so the agent never sees real tokens. Also with git worktrees, you can even run Claude and Codex in parallel on the same task and diff the results.
Qovery RDE for the remote agent.Qovery has industrialized the pattern in its Remote Development Environments offering. The platform engineering team defines a blueprint (IDE, databases, services, environment variables, RBAC) that gets cloned per developer via qovery rde create. Each builder receives a VS Code Server workspace accessible from the browser, with Claude Code, OpenCode, and GitHub Copilot pre-integrated. Isolation is total: no access to peers' environments or to production, project-scoped RBAC. TTL jobs automatically close forgotten environments.
SLM benchmarking and deployment. Pierre Lepagnol walks through a concrete decision framework:
Sensitive data?
Well-defined task?
Latency-critical?
High-volume?
One yes, you pick an SLM. POC methodology: build an evaluation set, get the cloud-LLM baseline, test 2-3 SLMs of different sizes (Gemma, SmolLM, Qwen, ...), iterate down to the smallest viable model. The cost-per-million-tokens comes out an order of magnitude below Anthropic.
Decision framework: when to pick an SLM over a SOTA cloud LLMSLM decision framework: one "yes" is enough to start the evaluation.
On the Qovery side, we see the same shift with our customers: engineering leads ask us about GPU instance types the way they used to ask about database tiers. How do we host inference? These are infrastructure questions now. Sovereignty became the default architectural assumption driven by regulation, inference pricing, and AI agents' security issues made it unavoidable.
Going home with a notebook full of homework
Three days, 20 talks, too much coffee. Devoxx France 2026 was intense, and somewhere in there my perspective on my own work shifted.
Big thanks to the speakers I mentioned and the dozens I didn't have room for. The videos are already available on the Devoxx France YouTube channel, and the links to the talks that fed this article are collected at the bottom of the page.
What I'm taking back to Qovery: more weight on context and harness engineering as a product surface; sharper thinking on the local sandboxed agent and RDEs as the place where security, cost, and agent isolation converge; and the conviction that on-premise SLMs will become a serious lever for teams constrained by sovereignty, cost, or latency. The pattern across all three truths is the same: AI changed the stakes, the fundamentals didn't, and the discipline we used to skip is the one we now have to lead with.
See you next year, Devoxx.
Talks referenced in this article
Videos are available in French with subtitles + automatic voice translation.
Fabien is a senior software engineer at Qovery. He writes about platform engineering, AI tooling, context engineering, and the practical realities of running modern developer infrastructure.
Next step
Run AI agents safely on infrastructure you control.
Qovery Remote Development Environments give your team isolated, governed workspaces with Claude Code, OpenCode, and Copilot pre-integrated - no SSH keys leaking to agents, no shadow inference bills.