Cut tool sprawl: automate your tech stack with a unified platform
Stop letting tool sprawl drain your engineering resources. Discover how unified automation platforms eliminate configuration drift, close security gaps, and accelerate delivery by consolidating your fragmented DevOps stack.
The Hidden Tax of Fragmentation: Maintaining a disconnected stack (Terraform, Helm, Jenkins, etc.) creates significant "glue code" debt, leading to configuration drift, security vulnerabilities, and slowed deployment velocity.
Consolidation Without Compromise: Unified platforms solve this by abstracting low-level complexity (like Kubernetes internals) while retaining the granular control and portability engineering teams require.
From Maintenance to Innovation: By adopting a platform like Qovery, teams can shift from managing toolchains to true Platform Engineering, enabling developer self-service (e.g., ephemeral environments) and scaling output without linearly scaling headcount.
The modern DevOps toolchain has mutated from an asset into a liability. What began as specialized solutions has evolved into a fragile ecosystem of platforms, scripts, and integrations that demands as much maintenance as the product itself.
A standard pipeline today forces teams to juggle GitHub, CI providers, Terraform, Helm, ArgoCD, and monitoring suites. The "glue code" connecting them is a constant maintenance burden, and every new tool adds configuration drift and security overhead. The result is friction: velocity tanks as engineers burn hours debugging the pipeline rather than shipping code.
The solution is not another tool - it is a fundamental shift in strategy. Engineering organizations must move toward unified platforms that consolidate this fragmented sprawl without sacrificing control. In this article, we explore the heavy cost of a fragmented setup and how a unified approach restores delivery speed.
The Hidden Costs of Fragmentation
The implementation of various tools for product teams to deliver their solution eventually generates multiple pain points for organizations to solve.
1. Configuration Drift
Each tool in the stack maintains its configuration separately. Terraform state files define infrastructure, while Helm charts configure applications, and CI/CD pipelines specify build steps. Environment variables scatter across multiple systems, often containing duplicated values, and requiring extended efforts during updates.
Over time, these configurations drift apart. Different environments no longer match production setup because of manual infrastructure updates. The CI pipeline assumes dependencies that Terraform no longer provisions or configuration variables are not updated in all environments identically.
Configuration drift creates unpredictable deployments. Code that works in development fails in staging for reasons unrelated to the code itself. Production incidents trace back to configuration inconsistencies that accumulated over months. Teams lose confidence in their deployment process and slow down to compensate.
2. Security Gaps
Every tool in the stack represents an attack surface and potential vulnerability for the organization. Each requires credentials, network access, and permissions to function. CI/CD systems need cloud provider credentials to deploy infrastructure. GitOps agents require cluster access to apply manifests and configuration. Monitoring tools have read access to logs and metrics across the platform.
Managing these credentials across a fragmented toolchain becomes a security challenge for operators to manage. Service accounts are created for various use cases while secrets spread across multiple vaults and configuration files. Access reviews must audit permissions across dozens of systems rather than a single platform.
Security vulnerabilities can compound across tools, for example, a compromised CI system provides access to deployment credentials and impacts the production environment. The more tools in the chain, the larger the attack surface and the harder it becomes to maintain consistent security posture.
3. The Kubernetes Complexity Barrier
Kubernetes promised to simplify container orchestration. In practice, it introduced a new layer of complexity that many teams struggle to manage effectively.
Running Kubernetes requires expertise in networking, storage, security policies, resource management, and the ever-expanding ecosystem of operators and extensions. Small teams without dedicated platform engineers find themselves spending more time learning Kubernetes than building their products.
The tooling around Kubernetes adds further complexity. Helm charts require templating knowledge, Kustomize overlays demand understanding of specific resource templating capabilities, service meshes introduce their configuration languages. Each layer of abstraction requires additional expertise.
Teams facing this complexity struggle to optimize all aspects of their infrastructure strategy. They either avoid Kubernetes entirely, missing its benefits for scalability and operational consistency, or they adopt Kubernetes with insufficient expertise, creating fragile deployments that can fail in unpredictable ways.
The Solution: The Unified Automation Platform
The answer to tool sprawl is consolidation without sacrifice. Unified automation platforms combine CI/CD, infrastructure management, Kubernetes orchestration, and observability into a single coherent system.
1. Abstraction Without Loss of Control
Effective platforms abstract complexity rather than hiding it. Engineers interact with high-level concepts like applications, environments, and deployments rather than low-level primitives like pods, services, and ingress rules. But the underlying infrastructure remains accessible when needed.
This abstraction model differs from fully managed platforms that provide convenience at the cost of control. Unified platforms run on your infrastructure, use standard technologies under the hood, and allow direct access to underlying systems. The abstraction simplifies common operations without preventing advanced configurations.
2. Consolidated Configuration
A unified platform maintains configuration in one place rather than scattered across tools. Environment definitions, deployment configurations, and infrastructure specifications live together with consistent syntax and semantics.
This consolidation eliminates configuration drift by design. Changes propagate consistently across environments. For example, with Qovery’s Native Terraform & OpenTofu Support, you can define infrastructure alongside your applications, automatically passing outputs (like database credentials) to your services without writing glue code.
3. Simplified Security Model
Centralizing the toolchain reduces the attack surface and potential for vulnerability. One platform requires one set of credentials, one access control system, and one audit log. Security reviews focus on a single system rather than dozens of integrations.
The platform manages credentials for underlying services internally. Engineers grant the platform access to cloud providers and Git repositories once, and individual tools no longer need direct access to sensitive resources.
Agents ship fast. Guardrails keep them safe.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.
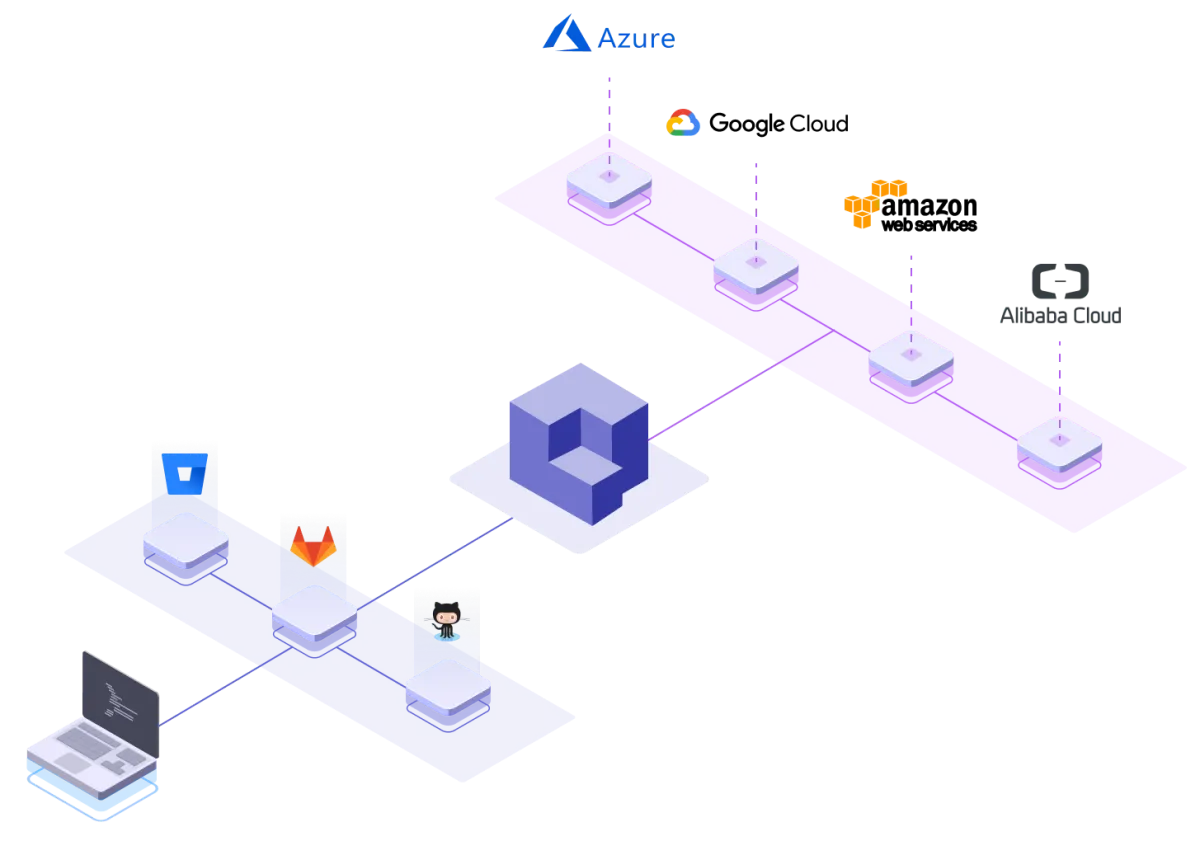
Qovery implements the unified platform model specifically for teams running on Kubernetes. The platform consolidates CI/CD, infrastructure provisioning, Kubernetes management, and observability into a single interface.
1. Eliminating Operational Toil
Qovery abstracts Kubernetes complexity, replacing the need to manage separate tools like ArgoCD, Helm, Terraform, and dedicated CI/CD systems. Developers deploy applications through Git push or web interface without writing YAML manifests or needing to understand Kubernetes internals.
The platform handles container building, registry management, deployment orchestration, and rollback automation. Operations that previously required coordinating multiple tools execute through a single workflow. Using this setup, teams eliminate the glue code and custom scripts that previously connected their toolchain.
2. Full Control and Portability
Qovery deploys and runs entirely on your existing AWS, GCP, or Azure account. Infrastructure provisions in your cloud, containers run on your Kubernetes clusters, and data stays within your security perimeter.
This model eliminates vendor lock-in concerns that prevent adoption of managed platforms. Teams retain full access to underlying resources. Migration away from Qovery leaves standard Kubernetes deployments that continue operating independently.
For platform engineers who need direct access, the underlying infrastructure remains fully accessible. Qovery simplifies common operations without preventing advanced configurations or custom integrations.
3. Developer Self-Service
The unified platform enables developers to deploy and manage environments without platform team involvement. Creating a new environment takes a few clicks, and deploying changes happens through familiar Git workflows.
Ephemeral environments become practical when environment creation is self-service. Each pull request receives an isolated preview environment automatically. Developers test changes in production-like conditions without competing for shared staging resources.
This self-service model dramatically improves deployment frequency and quality of life. Teams blocked by environment availability or deployment complexity now ship changes continuously. The platform handles the operational work that previously required dedicated DevOps support.
The Path to Platform Engineering
Unified platforms enable a fundamental shift in how DevOps teams operate. Rather than maintaining toolchains, teams focus on developer experience as their primary product.
1. From Tool Maintenance to Product Thinking
Traditional DevOps teams spend significant time on tool maintenance. Updating CI systems, patching security vulnerabilities, scaling infrastructure, and debugging deployment issues consume hours that could go toward improving developer workflows.
Unified platforms shift this balance. With toolchain maintenance consolidated, DevOps engineers focus on understanding developer needs and improving the platform experience. The role evolves from system administration toward product management for internal customers.
2. Building Internal Developer Platforms
Platform engineering treats the development platform as a product with developers as customers. Success metrics shift from uptime and incident counts toward developer satisfaction, deployment frequency, and time to first deployment.
Qovery provides the foundation for this platform engineering approach. Rather than building internal developer platforms from scratch, teams customize and extend a proven base. The platform handles infrastructure complexity while teams focus on workflows specific to their organization.
3. Scaling Without Proportional Headcount
Tool sprawl creates linear scaling challenges. More applications mean more pipelines, more configurations, and more maintenance. Teams grow headcount to manage growing complexity rather than improving the capability of their environments.
Unified platforms break this pattern. Adding applications requires minimal additional configuration. The platform scales automatically while the team focuses on high-value improvements rather than repetitive maintenance.
Conclusion
Tool sprawl has become the hidden tax on software delivery for scaling organizations. The complexity of maintaining fragmented toolchains slows deployment velocity, creates security gaps, and burns engineering time on maintenance rather than innovation.
Unified automation platforms offer a path forward. By consolidating CI/CD, infrastructure management, and Kubernetes orchestration into a single system, teams eliminate configuration drift, simplify security, and enable developers.
The shift requires recognizing that more tools do not equal better outcomes. The modern imperative is simplification through consolidation, abstraction without loss of control, and automation that empowers developers rather than creating new bottlenecks.
Melanie leads content at Qovery. She covers platform engineering trends, Kubernetes operations, FinOps, and the tools that help engineering teams ship faster.
Next step
Agents ship fast. Guardrails keep them safe.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.