Building a single pane of glass for enterprise Kubernetes fleets
A Kubernetes single pane of glass is a centralized management layer that unifies visibility, access control, cost allocation, and policy enforcement across § cluster in an enterprise fleet for all cloud providers. It replaces the fragmented practice of switching between AWS, GCP, and Azure consoles to govern infrastructure, giving platform teams a single source of truth for multi-cloud Kubernetes operations.
Fragmented multi-cloud management hides cost spikes, configuration drift, and security vulnerabilities across enterprise Kubernetes fleets, leading to audit failures and uncontrolled cloud spend.
A single pane of glass requires an active control plane that can provision, update, and enforce policy across clusters, not a passive dashboard that only reads metrics.
Centralizing RBAC, FinOps, and compliance under one management layer turns disparate multi-cloud infrastructure into a single, programmable compute pool.
Platform teams managing Kubernetes across multiple cloud providers spend their days switching between the AWS console, the GCP console, and the Azure portal to understand the state of their infrastructure.
With 89% of enterprises now operating on a multi-cloud strategy, this fragmented visibility does more than waste engineering hours. It hides cost spikes, configuration drift, and security vulnerabilities. Managing multiple control planes across EKS, AKS, and GKE directly increases the risk of orphaned workloads, open ports, and misplaced secrets.
These blind spots generate immediate financial waste. Current data shows that 27% of all IaaS and PaaS cloud spend is wasted globally. For FinOps teams and CTOs, this manifests as unexplained billing spikes at the end of the month, compounded by the fact that between 20%-40% of organizations struggle to accurately attribute their cloud spend specifically because of multi-cloud fragmentation.
The 1,000-Cluster Reality
Managing five clusters across two clouds is an annoyance that senior engineers absorb as part of their workflow, while managing 1,000 clusters globally is an operational liability that threatens the engineering organization. It reduces it’s ability to pass security audits, control cloud spending, and maintain consistent governance.
At this scale, the CTO and platform architects can no longer rely on individual engineers knowing about each cluster's configuration. The source of truth for RBAC policies, network configurations, cost allocations, and security posture ends up distributed across three different cloud vendor dashboards.
A single misconfiguration in one cluster out of a thousand, an overly permissive role binding, or an unpatched ingress controller becomes a compliance failure that auditors can raise. The pivot from small-scale multi-cloud to enterprise fleet management demands a centralized governance layer that treats every cluster as part of a single compute unit.
🚀 Real-world proof
Hyperline needed to scale their infrastructure across multiple environments without the overhead of a dedicated DevOps team.
The Cost of Fragmented Fleet Management
The RBAC Nightmare
Each cloud provider implements its own identity and access management layer on top of Kubernetes RBAC. EKS uses IAM roles mapped to Kubernetes groups through aws-auth ConfigMaps. GKE ties access to Google Cloud IAM with Workload Identity. AKS integrates with Microsoft Entra ID for authentication and authorization.
Maintaining separate IAM configurations, Roles, and RoleBindings for each provider means that a permission change intended to be fleet-wide requires various separate implementations, each with its own syntax and particularities. At fleet scale, this fragmentation makes it functionally impossible to answer the question “who has access to what” without an extensive audit.
Blind Spots in Compliance
Security policies applied per-cluster instead of globally create compliance drift that is invisible until an audit exposes it. A pod security standard enforced on production clusters in AWS may be missing from staging clusters in GCP, while a network policy restricting egress traffic may exist in one region but not in another.
Each cluster that deviates from the intended security baseline represents an uncontrolled risk, and without a centralized view of policy state across the fleet, the platform team has no way to easily detect these deviations proactively. The drift compounds over time as teams apply hotfixes, rotate certificates, or update configurations on individual clusters without propagating those changes globally.
FinOps and Runaway Cloud Spend
Native cloud billing dashboards report costs at the account or project level, not at the application or team level within a Kubernetes cluster. When a fleet spans AWS, GCP, and Azure, there is no single view that shows which application on which cluster in which region is consuming what resources.
Platform teams cannot optimize what they cannot see. Cost allocation at the Kubernetes level requires mapping pods, namespaces, and labels to business units, and none of the native cloud consoles provide this granularity across providers.
Without application-level unit economics across the fleet, FinOps teams are left reconciling three separate billing systems with no way to attribute shared cluster costs to the teams that generate them.
Managing 100+ K8s Clusters
From cluster sprawl to fleet harmony, master the operational strategies and architectural frameworks required to orchestrate high-performing, global, AI-ready Kubernetes fleets.
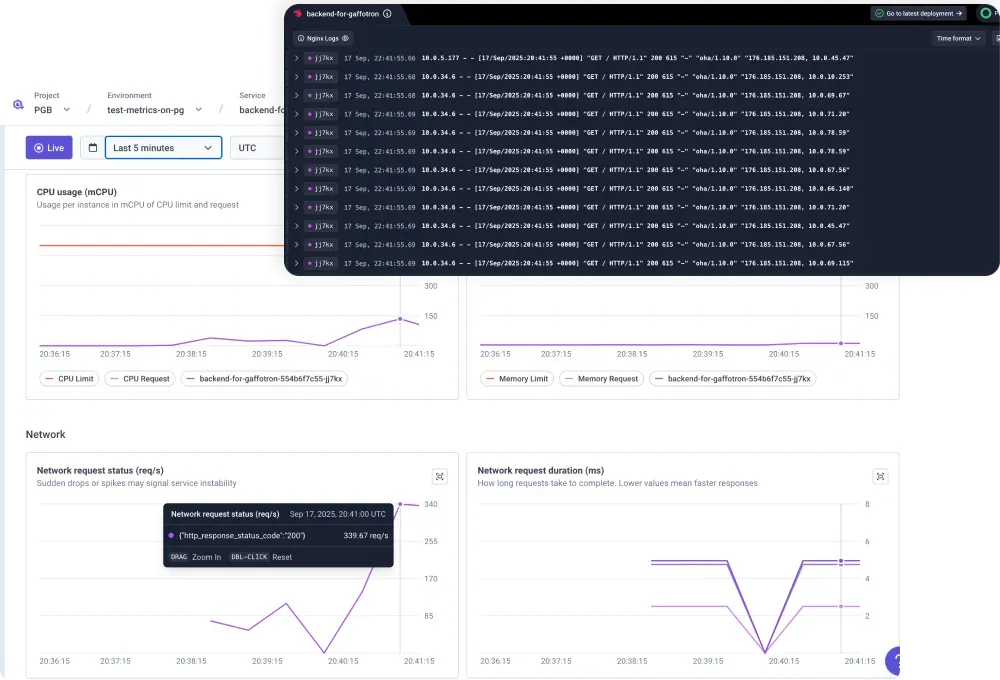
A common misconception is that a Grafana dashboard stitching together metrics from multiple clusters constitutes a single pane of glass. However, telemetry is not governance, as a dashboard that reads metrics and indicators provides visibility into what is happening but cannot act on what it finds.
Platform teams at fleet scale need an active control plane that can provision new clusters, apply policy updates across the fleet, update RBAC bindings, and delete orphaned resources. The distinction matters: a passive dashboard tells you that a cluster is drifting from its intended configuration, while an active control plane prevents the drift from persisting.
Observability and governance are complementary but architecturally distinct, and conflating them is why many organizations believe they have fleet management solved when they have only solved monitoring.
Qovery: The Agentic Control Plane for Enterprise Fleets
Qovery functions as the centralized management layer that sits above EKS, GKE, and AKS. It connects to managed Kubernetes clusters in the organization's own cloud accounts and registers them within a single organizational structure.
From that unified interface, platform teams provision clusters, deploy applications, enforce security policies, and allocate costs across the entire fleet without switching between cloud consoles. The platform translates global policies into provider-specific actions.
A deployment rule defined once in Qovery applies to every cluster in the fleet, whether that cluster runs on AWS, GCP, or Azure. Resource limits, environment lifecycle rules, and security boundaries propagate automatically, eliminating the per-cluster, per-provider configuration work that consumes platform engineering time at scale. This removes the need for teams to maintain separate YAML configurations per cloud provider, as the control plane abstracts the provider-specific translation.
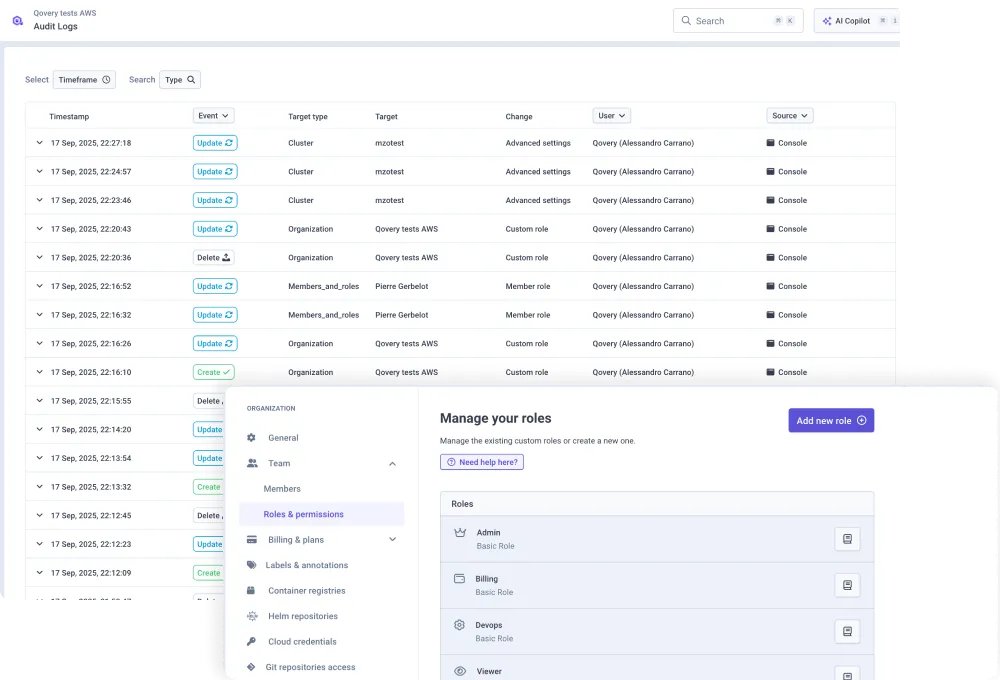
Centralizing RBAC and Governance
Connecting an identity provider like Entra ID or Okta to the control plane allows platform teams to map user permissions across hundreds of clusters from a single configuration. When an engineer joins a team, their role assignment in the IdP propagates to every cluster where that team has workloads. When an engineer leaves, revoking access in the identity provider revokes it across the entire multi-cloud fleet instantly, without touching individual cluster configurations on EKS, GKE, or AKS.
This centralized RBAC model also enables granular audit trails. Every action taken through the control plane is logged with the identity, timestamp, target cluster, and specific change applied. For organizations operating in regulated sectors, this audit trail satisfies compliance requirements that would otherwise demand manual evidence collection across every cluster in the fleet. The RBAC configuration becomes a single source of truth rather than a fragmented set of provider-specific bindings that must be reconciled during each audit cycle.
Standardizing Day-2 Operations
True fleet management requires treating disparate multi-cloud infrastructure as a single, programmable compute pool. The architectural necessity of a unified control plane extends beyond the convenience of a single dashboard.
It is the mechanism through which platform teams enforce consistent day-2 operations across every cluster: upgrades, patching, certificate rotation, cost allocation, and access control all flow from one policy layer rather than being implemented independently per cluster and per provider.
Organizations that reach fleet scale without this centralization spend an increasing percentage of their platform engineering capacity on reconciliation work: verifying that configurations match across clouds, auditing RBAC bindings that have drifted, and investigating cost anomalies that native billing tools cannot explain.
A unified control plane eliminates these categories of work by making consistency the default, bringing visibility to all users, and helping engineering organizations proactively correct and improve infrastructure.
FAQs
How does a single pane of glass differ from a Grafana dashboard for Kubernetes fleet management?
A Grafana dashboard aggregates metrics and provides read-only visibility into cluster health. A true single pane of glass is an active control plane that can provision, configure, and enforce policies across clusters. Telemetry shows what is happening, while governance determines what is allowed to happen. Fleet management at scale requires both, but they serve different architectural functions.
Can you centralize RBAC across EKS, GKE, and AKS without a unified control plane?
Each provider implements identity and access differently: EKS uses IAM role mappings, GKE uses Google Cloud IAM with Workload Identity, and AKS integrates with Entra ID. Without a layer that abstracts these differences, every permission change requires three separate implementations. A unified control plane connected to an IdP like Okta or Entra ID maps permissions once and propagates them across all providers automatically.
How does centralized fleet governance improve FinOps for multi-cloud Kubernetes?
Native cloud billing dashboards report at the account level, not at the application or namespace level within Kubernetes. Centralized governance maps pod and namespace resource consumption to teams and business units across providers, enabling application-level cost attribution that no single cloud console can provide. This visibility is what makes optimization possible at fleet scale.
Melanie leads content at Qovery. She covers platform engineering trends, Kubernetes operations, FinOps, and the tools that help engineering teams ship faster.
Next step
Agents ship fast. Guardrails keep them safe.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.