Overview
This guide shows you how to use Qovery Lifecycle Jobs to seed your PostgreSQL database with SQL scripts. This approach is ideal for initializing databases with sample data, setting up database schemas, or restoring database backups during deployment.What are Lifecycle Jobs? Lifecycle Jobs are special jobs in Qovery that run at specific events during your application lifecycle, such as START, STOP, or DELETE. They’re perfect for database initialization, migrations, and cleanup tasks.
Prerequisites
- A Qovery account with an environment set up
- A PostgreSQL database deployed in your Qovery environment
- A SQL script file for seeding your database
- Basic knowledge of Docker and shell scripting
Goal
Set up an automated database seeding process that runs when your environment starts, using a secure approach that downloads SQL scripts from external storage (like S3) and executes them against your PostgreSQL database.Architecture Overview
The solution consists of three main components:- Dockerfile: Builds a container with PostgreSQL client and curl
- Seed Script: Shell script that downloads and executes SQL files
- Lifecycle Job: Qovery job configured to run at environment start
Step 1: Prepare Your SQL Script
First, prepare your SQL script and store it in a secure location.Step 2: Create the Seeding Script
Create a shell script that will download and execute your SQL file.Create seed.sh
Create a file named
seed.sh with the following content:seed.sh
- psql: Used for plain SQL files (.sql)
- pg_restore: Used for custom PostgreSQL dump formats (.dump, .backup)
Step 3: Create the Dockerfile
Create a Dockerfile that packages the seeding script with required dependencies.Step 4: Create Lifecycle Job in Qovery
Now create the Lifecycle Job in the Qovery Console.Open Qovery Console
Navigate to Qovery Console and select your environment.
Configure Repository
Configure the service:
- Name:
database-seed - Source: Select your Git provider and repository
- Branch:
main(or your default branch) - Root application path: Leave empty if Dockerfile is at root, or specify path if in subdirectory
Select Lifecycle Event
- Event: Select START
You can also select multiple events if needed:
- START: Run when environment starts
- STOP: Run when environment stops
- DELETE: Run when environment is deleted
Configure Job Settings
- Number of restarts: 0 (job should run once and complete)
- Max duration: 300 seconds (adjust based on your database size)
- Port: Leave empty (not needed for this job)
- CMD Arguments:
["seed.sh"]
Configure Resources
Set appropriate resources: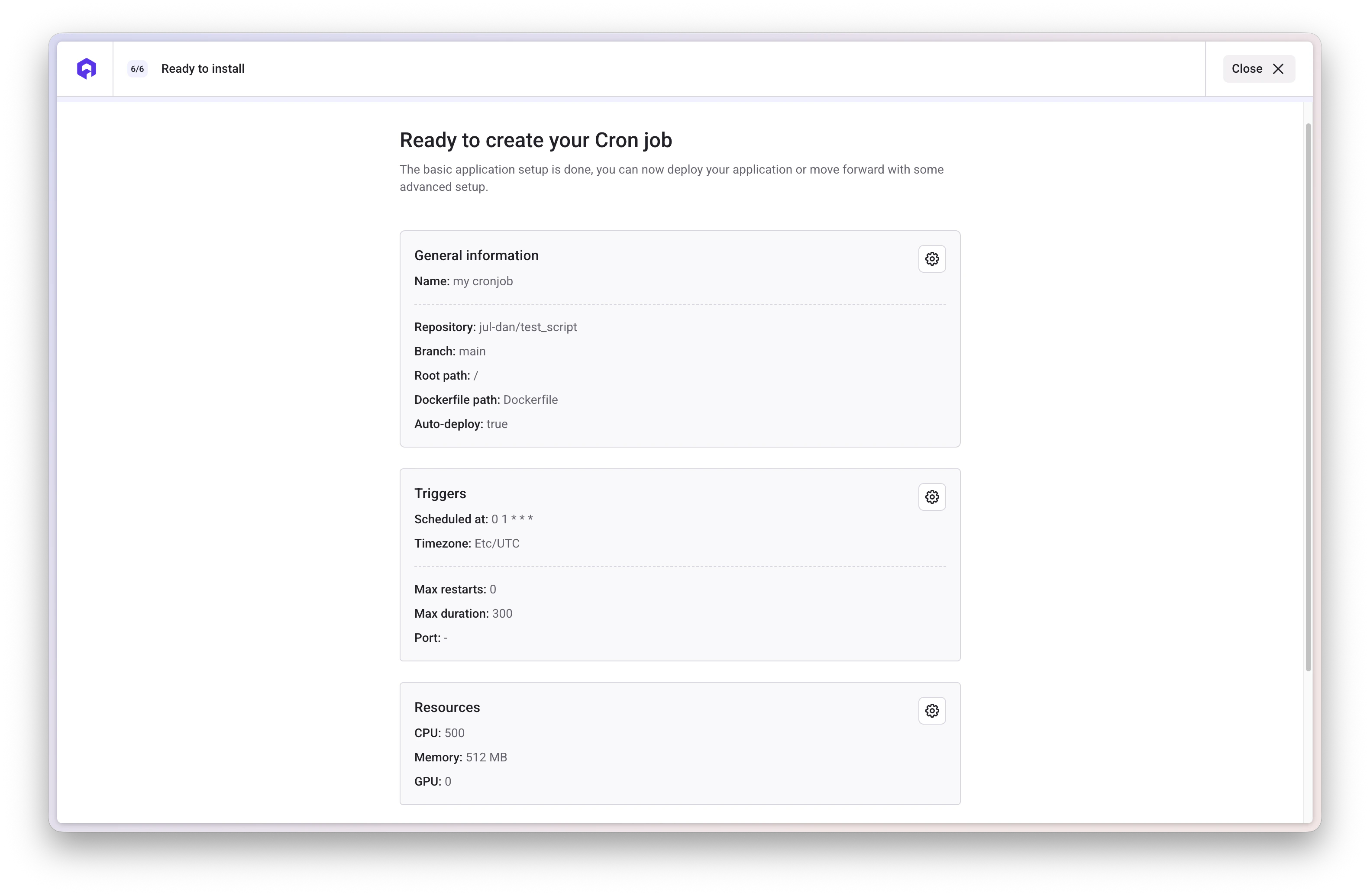
- CPU: 0.5 vCPU (adjust based on database size)
- Memory: 512 MB (adjust based on SQL file size)
Step 5: Configure Environment Variables
Configure the environment variables required by your seeding script.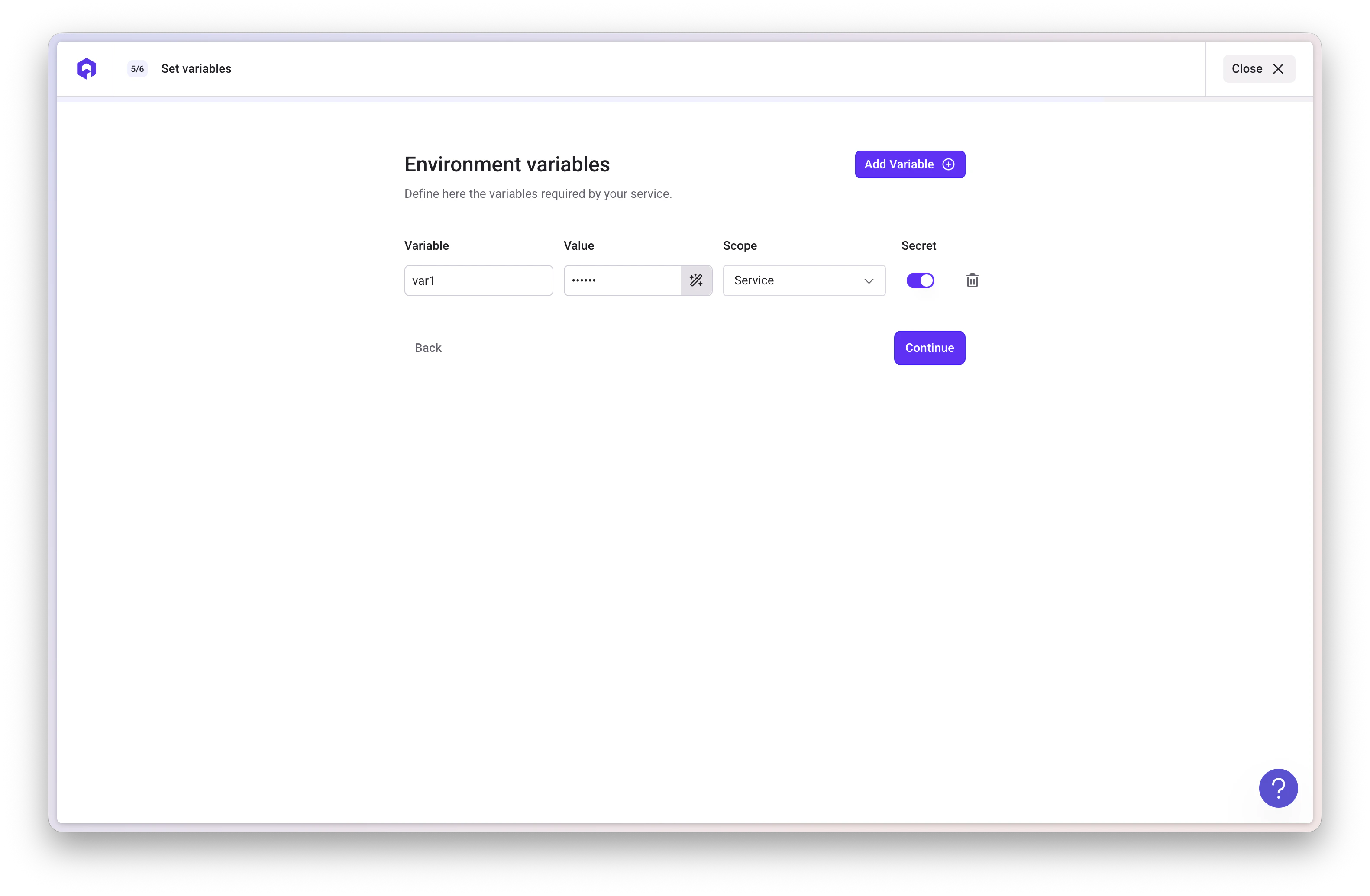
Add DATABASE_URL
Add the database connection string:
- Variable:
DATABASE_URL - Value: Use the built-in alias from your PostgreSQL service
- Type: Alias
Using Qovery Database Aliases: If your PostgreSQL database is deployed in Qovery, you can reference it using built-in aliases like
$QOVERY_DATABASE_YOUR_DB_NAME_CONNECTION_URI. This automatically provides the connection string.Add SEED_URL
Add the URL to your SQL script:
- Variable:
SEED_URL - Value: The URL to your SQL script (e.g., S3 presigned URL)
- Type: Secret (if URL contains sensitive information)
Step 6: Deploy and Test
Deploy your Lifecycle Job and verify it works correctly.Deploy the Lifecycle Job
Click Deploy to start the deployment.The job will build the Docker image and wait for the next lifecycle event.
Trigger the Job
The seeding job will automatically run when:
- You deploy or redeploy your environment
- You start a stopped environment
- The START event is triggered
Check Job Logs
View the Lifecycle Job logs to verify successful execution: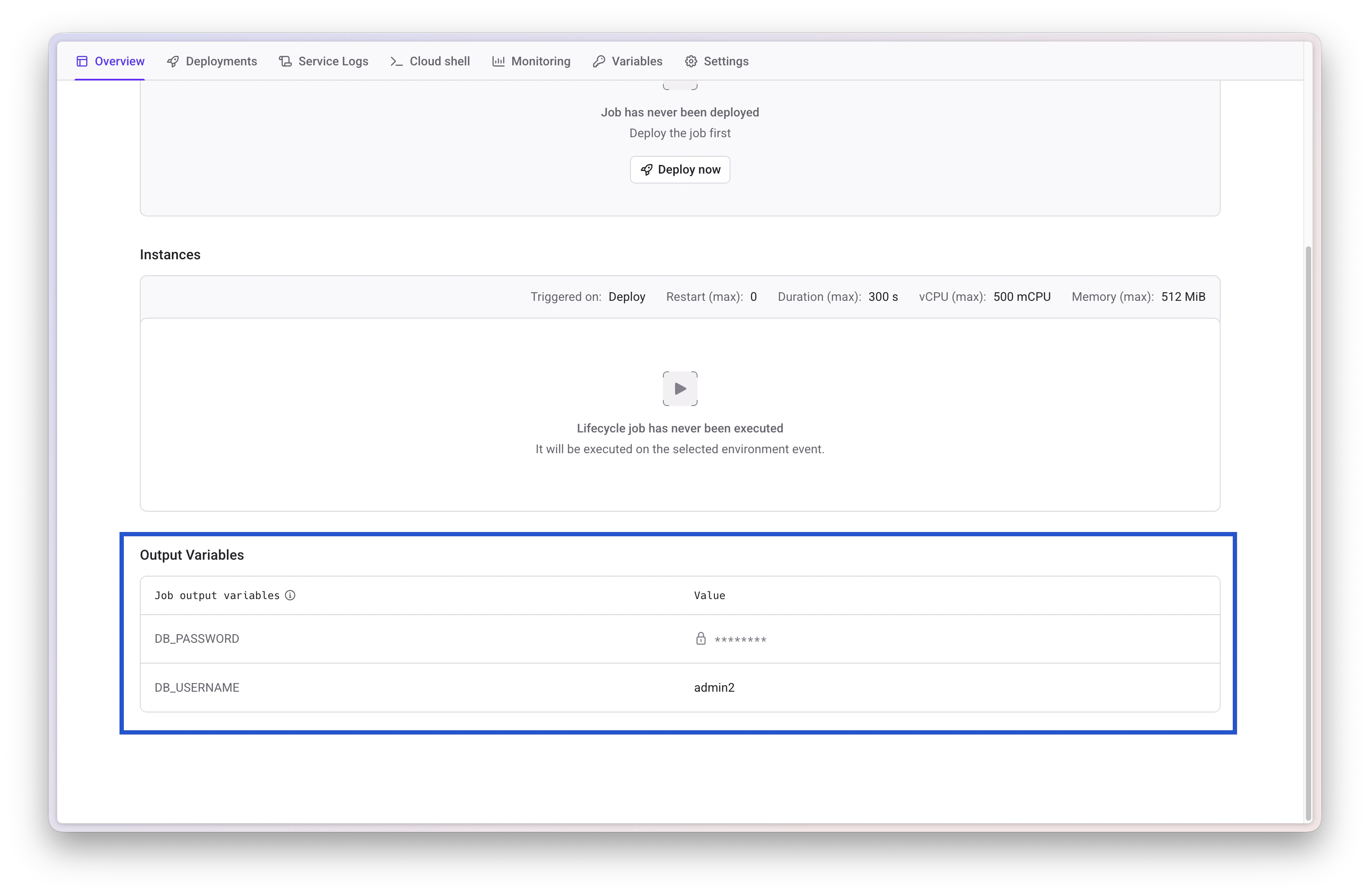
Advanced Scenarios
Idempotent Seeding
To make your seeding script safe to run multiple times, use idempotent SQL commands:Using Multiple SQL Files
Modify your seed script to handle multiple SQL files:Conditional Seeding
Only seed if database is empty:Environment-Specific Seeds
Use different seed files for different environments:Troubleshooting
Job Fails with “psql: command not found”
Issue: PostgreSQL client not installed in container Solution: Verify your Dockerfile installspostgresql-client:
Connection Timeout to Database
Issue: Cannot connect to database from Lifecycle Job Checklist:- ✅ Database is deployed and running
- ✅
DATABASE_URLenvironment variable is correctly set - ✅ Database and Lifecycle Job are in the same environment
- ✅ Network connectivity between services is enabled
SQL File Download Fails
Issue: Cannot download SQL file from storage Solution:- Verify the
SEED_URLis correct and accessible - Check if presigned URLs have expired (regenerate if needed)
- Ensure the container has network access to external URLs
- Test the URL manually with curl
Duplicate Key Errors
Issue: Seeding fails with duplicate key violations Solution: Use idempotent SQL commands:Job Runs Too Long and Times Out
Issue: Seeding job exceeds max duration Solution:- Increase the Max duration in job settings
- Optimize your SQL script (use COPY instead of INSERT for large datasets)
- Split large seeds into multiple smaller files
- Consider using
pg_restorewith parallel jobs flag for large dumps
Best Practices
Store Secrets Securely
Store Secrets Securely
Never commit sensitive data to your Git repository:
- Use presigned URLs with expiration for S3
- Store SQL files in private buckets with IAM authentication
- Use Qovery Secrets for sensitive environment variables
- Rotate presigned URLs regularly
Make Seeds Idempotent
Make Seeds Idempotent
Design your SQL scripts to be safely re-runnable:
- Use
CREATE TABLE IF NOT EXISTS - Use
INSERT ... ON CONFLICT DO NOTHING - Check for existing data before inserting
- Use transactions to ensure all-or-nothing execution
Environment-Specific Data
Environment-Specific Data
Use different seed data for different environments:
- Minimal data for development
- Realistic test data for staging
- Migration scripts only for production
- Use environment variables to select appropriate seeds
Monitor Job Execution
Monitor Job Execution
Always check job logs after deployment:
- Verify successful completion in Qovery logs
- Check database contents after seeding
- Set up alerts for job failures
- Review execution time to optimize performance
Version Control Your Seeds
Version Control Your Seeds
Track changes to your seed data:
- Keep seed SQL files in version control
- Use semantic versioning for seed files
- Document changes in commit messages
- Tag releases that include seed changes
Test Before Production
Test Before Production
Always test database seeding in non-production environments:
- Test with preview environments
- Verify on staging before production
- Test rollback procedures
- Document the seeding process
Alternative Approaches
Using Database Migrations
For schema changes and ongoing database updates, consider using migration tools instead:- Flyway: Version-controlled database migrations
- Liquibase: Database-independent migration management
- Alembic: Python-based migration tool for SQLAlchemy
- TypeORM/Sequelize: Built-in migration support for Node.js
Using Qovery Clone Environment
For duplicating existing data:- Create a database backup in your source environment
- Use Qovery’s Clone Environment feature
- The cloned environment includes database snapshots
Using Init Containers (Helm)
If deploying with Helm charts, use init containers:Additional Resources
Lifecycle Jobs Documentation
Complete guide to Qovery Lifecycle Jobs
Environment Variables
Managing environment variables and secrets
PostgreSQL Database
Deploying and managing PostgreSQL databases
Example Repository
Complete working example on GitHub
Next Steps
Now that you’ve set up database seeding, you can:- Create environment-specific seed files for development, staging, and production
- Implement database migrations for schema changes
- Set up automated testing with seeded test data
- Use Preview Environments with fresh seed data for each PR
- Explore other Lifecycle Job use cases (backups, cleanup, monitoring)