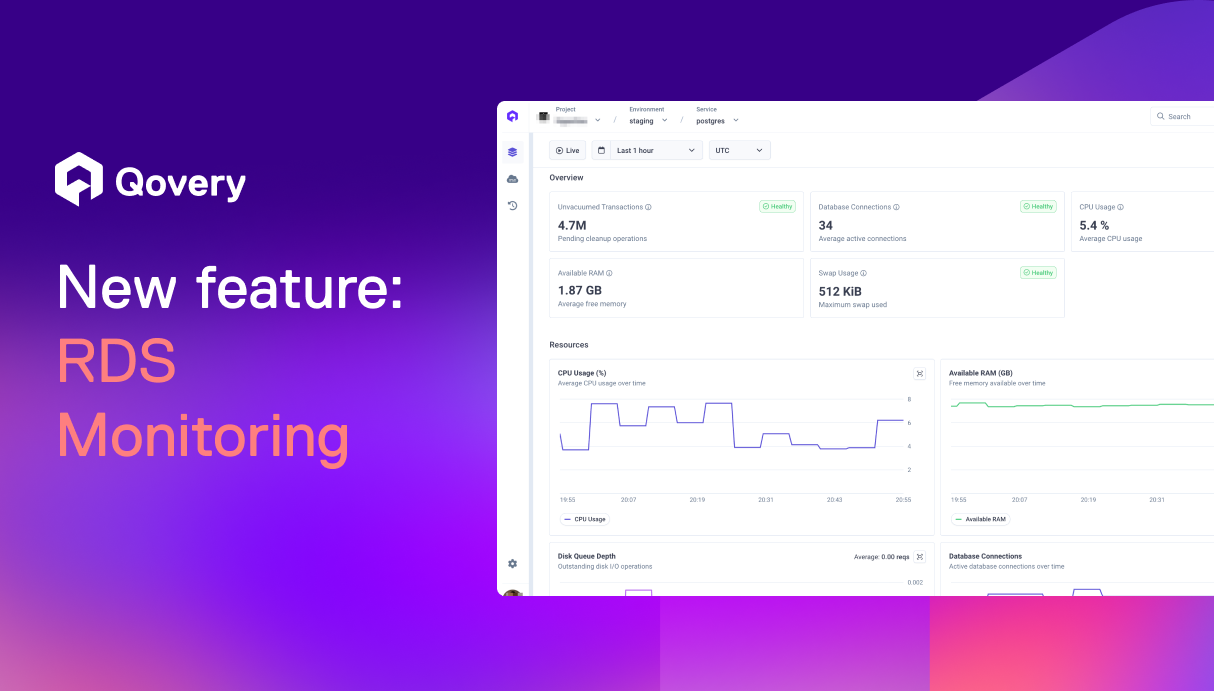
Starting today, get full visibility on your RDS databases directly inside Qovery. Troubleshoot app and database issues from one place without jumping into the AWS console
The real problem behind incident resolution - Databases
When an incident hits, teams often struggle to understand if the root cause is coming from the application or the database. Developers and DevOps jump between different tools, dig through the AWS console, try to find the right CloudWatch view, and manually correlate timestamps between their app logs and RDS metrics. This slows down diagnosis at the exact moment when time matters most.
When Qovery Observe kicks in
Qovery centralizes observability together with deployment and provisioning, creating a unique experience for developers.
Because Qovery already helps teams deploy and manage RDS instances with almost no friction, adding direct RDS monitoring inside the platform was the natural next step.
By exposing technical metrics like CPU, memory, and disk usage directly inside Qovery, teams can troubleshoot Kubernetes workloads and their RDS databases in one place, without jumping back and forth between consoles.
Outcomes for your team
Clearer visibility: your team gets immediate access to the right RDS metrics without navigating the AWS console, so you always know how your database behaves during incidents and peak traffic
Faster troubleshooting: no more guessing if the bottleneck sits in the app or the database. You can spot CPU spikes, memory pressure, or storage saturation in seconds and act right away
Less context switching: everything lives where your deployments, logs, and events already are. This removes the cognitive overhead of juggling multiple tools during stressful debugging sessions
Easier understanding of complex metrics: technical data like IOPS or disk throughput becomes easier to interpret when displayed next to your application activity. It gives developers more confidence when investigating database issues
Agents ship fast. Guardrails keep them safe.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.
A team noticed that their staging API was slowing down, but they could not tell if the issue was coming from their service or the underlying RDS database. Before, they had to browse through the AWS console, locate the right CloudWatch charts, switch back to their application logs, and compare timestamps manually. With Qovery RDS monitoring, they spotted a CPU spike and an IOPS saturation on the database directly from the same place where they investigate their application. The issue was identified and fixed in minutes instead of hours.
How to use it
Open your environment in Qovery and select the RDS database you want to inspect
Switch to the Observability tab to view live and historical metrics
Correlate DB anomalies with your environment events in seconds
Curious to see how it looks like? Check-out this video
Try it now
This feature is available for all customers who have Qovery Observe enabled. If it is not yet active for your organization, contact your CSM to have it enabled.