Discover how Qovery leverages its own platform to accelerate AI development. Learn how an AI specialist deployed a complex stack; including LLMs, QDrant, and KEDA - in just one day without needing deep DevOps or Kubernetes expertise. See how the "dogfooding" approach fuels innovation for our DevOps Copilot.
At Qovery we use our own products every day. We believe it is the fastest way to build empathy for our users and push innovation further. Whether it’s a frontend engineer using Preview Environments to test a pull request in isolation or our backend team refining our API, Qovery is the heartbeat of our development lifecycle.
But today is another story, we’re taking you behind the scenes to show how we use Qovery to speed up our new AI initiative.
We’ve been busy developing our [AI DevOps Copilot](https://www.qovery.com/ai-devops-copilot)**,** an AI assistant designed to redefine how developers interact with infrastructure. Our goal was simple: help developers and DevOps teams resolve daily operational headaches so they can stay focused on strategic, high-value work.
To build this, we needed the right talent. We found an incredible AI expert to lead the initiative. He is a master of Large Language Models (LLMs) and data science, but like many specialized developers, his expertise isn't in infrastructure, Kubernetes clusters, DNS configuration, or deployment management.
In a typical setup, this engineer would have spent weeks waiting for a Senior Reliability Engineer (SRE) to:
Set up CI/CD pipelines.
Configure Kubernetes and Helm charts.
Manage DNS and SSL certificates.
Provision databases and monitoring.
Weeks of back-and-forth, copy/pasting of YAML configuration to put in place even before his code can reach its target, clients.
How He Plugged the AI Stack into Qovery
For our AI lead, the challenge wasn't just writing the code; it was ensuring that code could talk to the right data and scale on demand. Here is exactly how he "plugged" the AI stack into Qovery:
Connecting the Brain (LLM & QDrant):
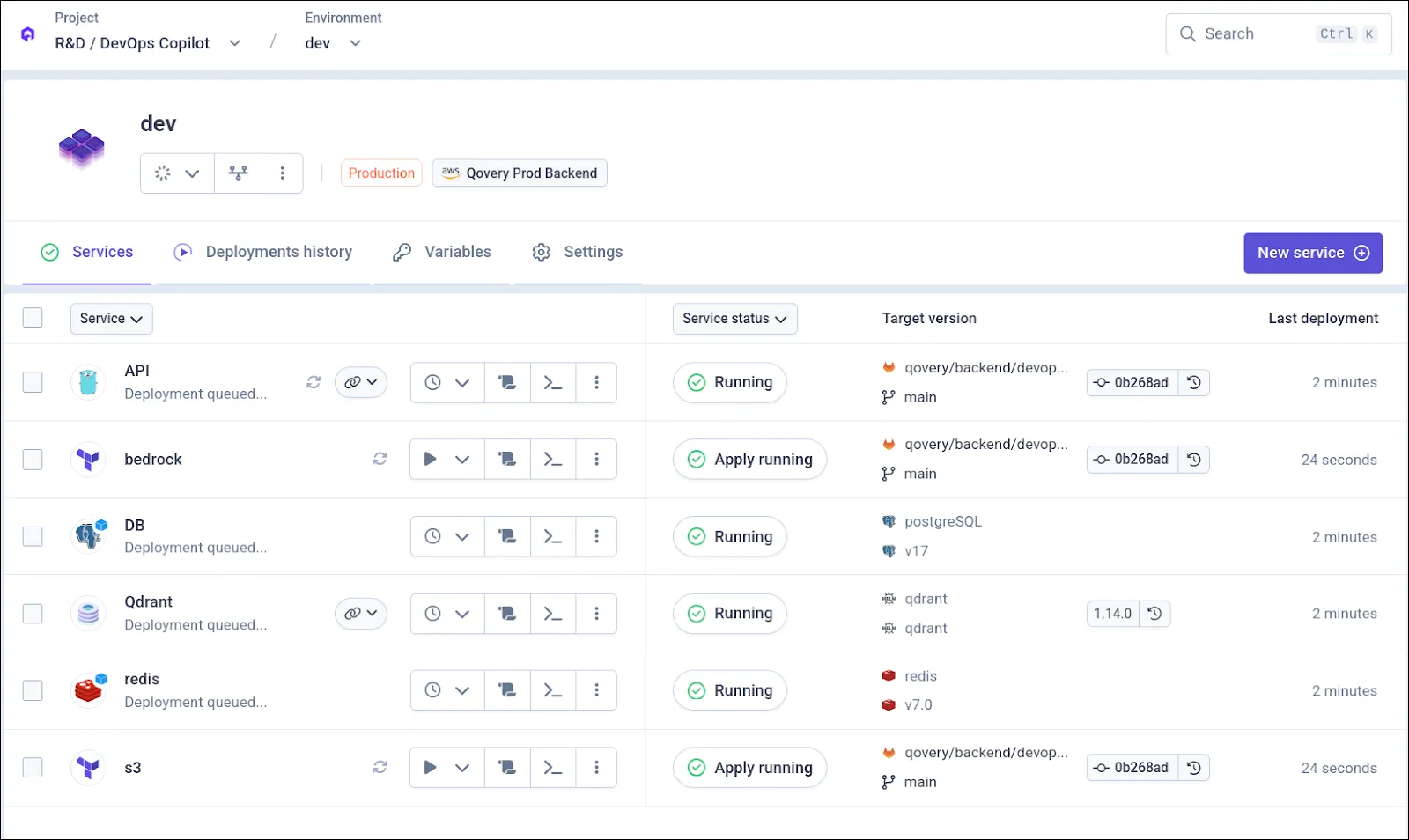
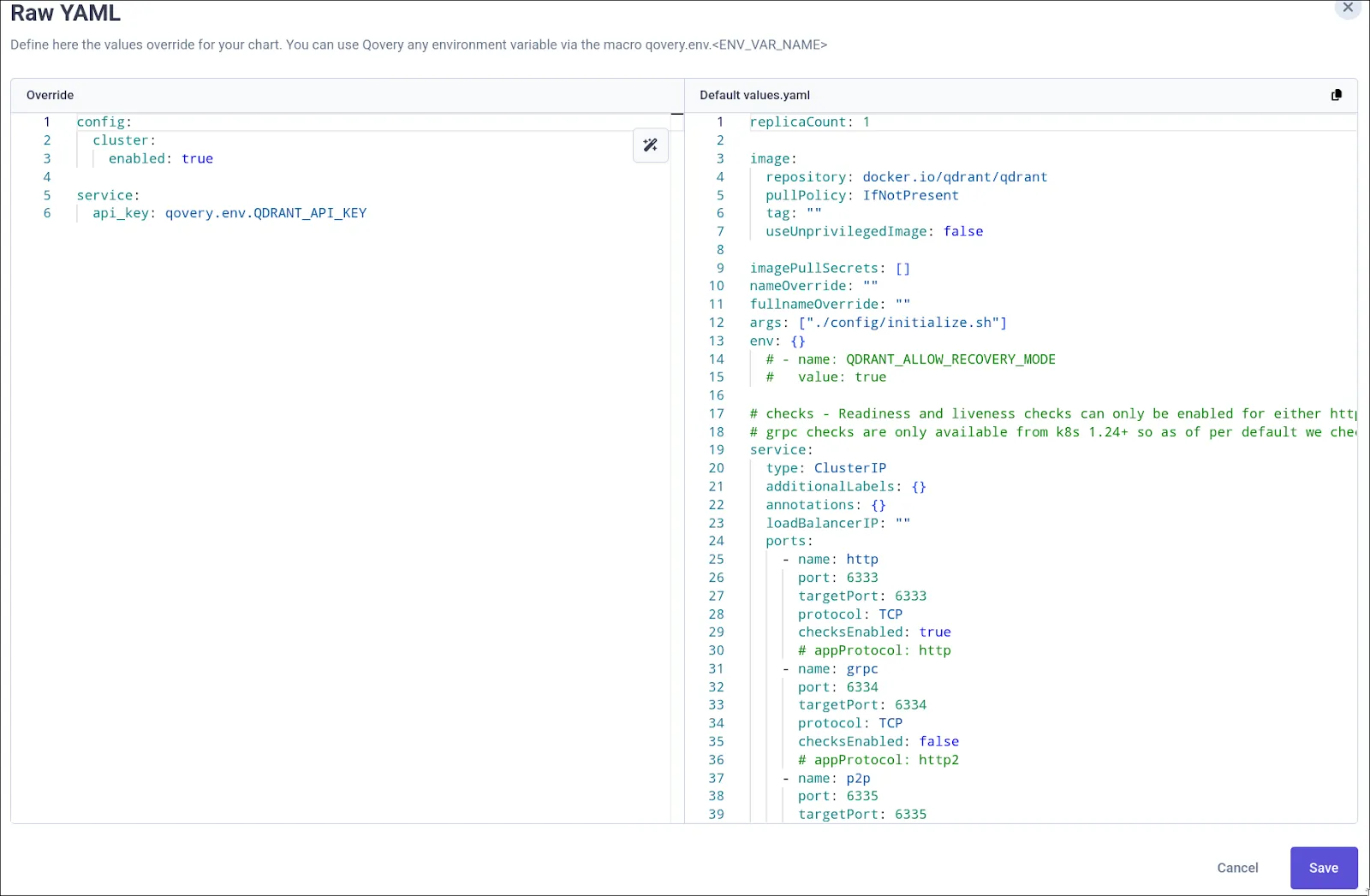
The core part of the application containing the agent and MCP server is built using our automatic docker image builder pipeline and request on-demand GPU nodes during deployment. To function, it needs to connect to databases; while Qovery provides ready-to-deploy SQL databases, we initially lacked a solution for vector databases like Qdrant to store model embeddings. To solve this, we leveraged Qovery’s Helm deployment system to deploy the official chart of QDrant, without the need for our AI lead to touch any CI/CD pipeline.
Automated scaling with KEDA
Since some operations of the agent can require a lot of memory, we enabled our beta autoscaling based on KEDA. This ensures we have the correct number of replicas to handle the load and set a readiness probe to stop serving traffic once a threshold is reached.
Managing the "State" with Terraform
As the product grows, so do its dependencies; our AI lead soon needed to store data into object storage. Instead of opening a ticket to our SRE to handle the creation of the S3 bucket, he used Qovery’s new Terraform integration to manage the lifecycle of S3 bucket directly within him environment, making him completely autonomous.
Agents ship fast. Guardrails keep them safe.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.
With Qovery, our AI lead pushed his application to production in a single day. He didn't just "deploy code"; he deployed a production-grade system with all the "safeties" an SRE requires, handled automatically by the platform:
Automatic Rollbacks: Instant recovery if a new model version fails liveness probes.
Deterministic Builds: Using Docker to ensure the AI environment is identical from local to prod.
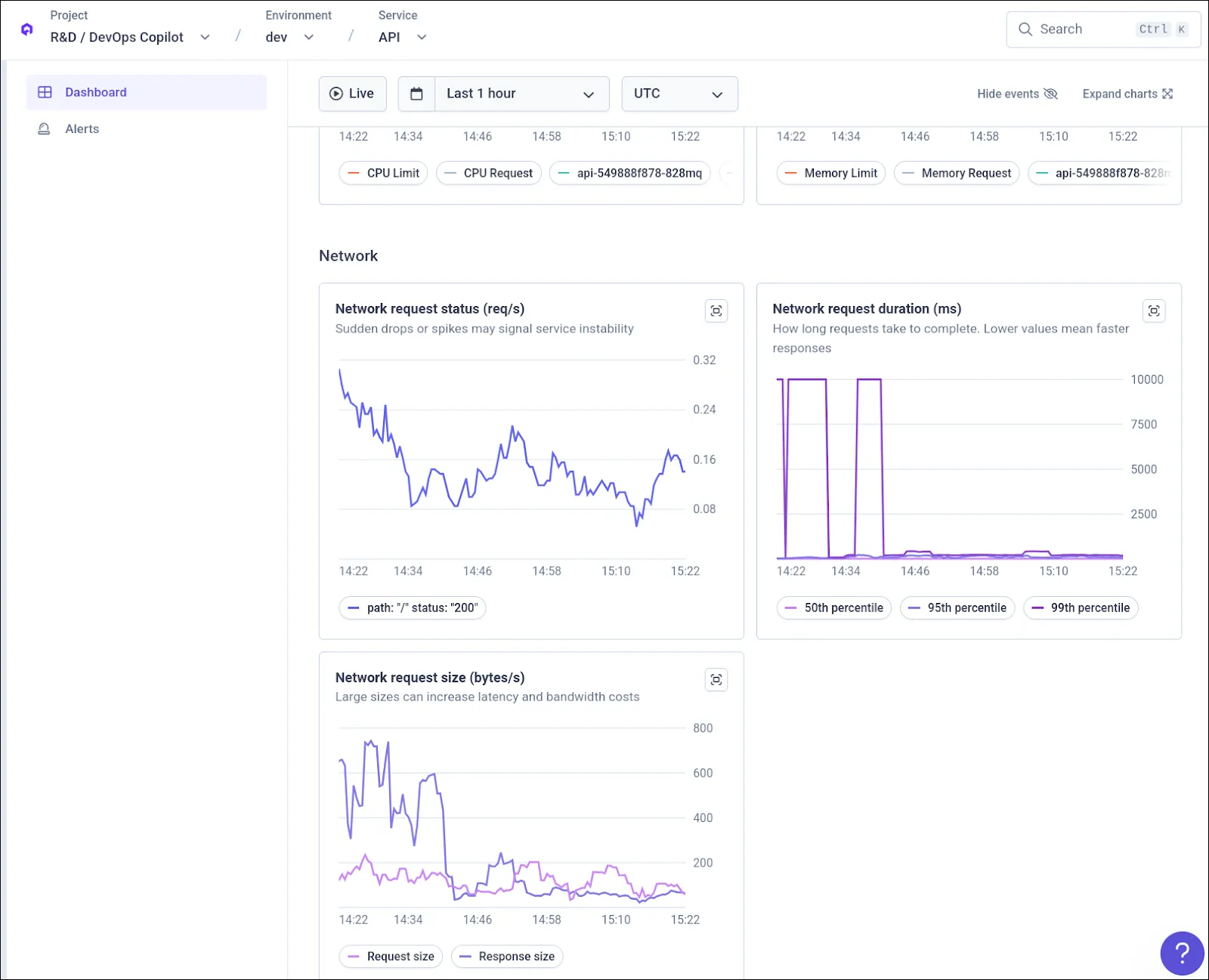
Full Observability: Real-time monitoring to observe the live state of the agent's performance.
Conclusion: Infrastructure as Leverage
We are really proud of our new AI DevOps Copilot initiative, It proves what we’ve always believed: Infrastructure should be leverage and AI is a big advantage for the future
Qovery has become the platform we envisioned: a place where developers are empowered to move at the speed of their ideas, and DevOps teams know the guardrails are baked into the system.
Romain is a staff engineer at Qovery working on the control plane and AI integrations. He writes about distributed systems, incident response, and MCP-based tooling.
Next step
Agents ship fast. Guardrails keep them safe.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.