Overview of the Deployment Pipeline
Understanding the deployment pipeline is the first step toward optimization.
One of the most critical aspects of a developer's workflow is reducing deployment time. While Qovery does a lot of heavy lifting to make your deployments faster and more efficient, there are still ways to fine-tune the process on your end. This guide will help you optimize deployment time across three essential phases: Build, Deployment, and Runtime.


Understanding the deployment pipeline is the first step toward optimization.
The pipeline usually involves:
Tip: It's worth noting that the "Build" phase often consumes the most time in the entire deployment process. Being aware of this can help you prioritize your optimization efforts effectively.
Before diving into optimizations, it's important to identify bottlenecks. The qovery environment deployment explain command can help you understand where your deployment spends most of its time, giving you actionable insights.
First, by listing your deployments
~ $ qovery environment deployment list --environment pr-234-preview-env
Id | Deployed At | Status | Duration
aa190093-9b25-4c7c-8cbf-2c59eec4929d-80 | 2023-09-03 06:59:06.720797 +0000 UTC | DEPLOYED | 18 minutes and 30 seconds
aa190093-9b25-4c7c-8cbf-2c59eec4929d-79 | 2023-09-02 19:59:06.016984 +0000 UTC | STOPPED | 9 minutes and 42 seconds
aa190093-9b25-4c7c-8cbf-2c59eec4929d-78 | 2023-09-02 08:35:51.976011 +0000 UTC | DEPLOYED | 2 minutes and 32 seconds
aa190093-9b25-4c7c-8cbf-2c59eec4929d-77 | 2023-09-02 06:59:05.095055 +0000 UTC | DEPLOYED | 14 minutes and 38 seconds
aa190093-9b25-4c7c-8cbf-2c59eec4929d-76 | 2023-09-01 19:59:04.156302 +0000 UTC | STOPPED | 9 minutes and 24 seconds
...
And then by getting the details of the deployment of our choice
~ $ qovery environment deployment explain --level step --id fae5c3aa-ae74-4560-b988-9f029a726533-1 --environment pr-234-preview-env
.
└── Environment: pr-234-preview-env [duration: 14 minutes and 58 seconds]
├── Stage 1: Databases [duration: 5 minutes and 31 seconds]
│ ├── Terraform RDS [duration: 4 minutes and 55 seconds]
│ │ ├── Step 1: Build [duration: 37 seconds]
│ │ └── Step 2: Deploy [duration: 4 minutes and 6 seconds]
│ ├── DB [duration: 1 minute and 13 seconds]
│ │ └── Step 1: Deploy [duration: 1 minute and 11 seconds]
│ ├── Redis [duration: 1 minute and 22 seconds]
│ │ └── Step 1: Deploy [duration: 1 minute and 22 seconds]
│ ├── My DB [duration: 1 minute and 22 seconds]
│ │ └── Step 1: Deploy [duration: 1 minute and 22 seconds]
│ └── SQS [duration: 3 minutes and 11 seconds]
│ ├── Step 1: Deploy [duration: 3 minutes and 11 seconds]
│ └── Step 2: Deployed [duration: 1 minute and 44 seconds]
├── Stage 2: Migration and Seed [duration: 1 minute and 18 seconds]
│ └── DB Seed Script [duration: 1 minute and 13 seconds]
│ ├── Step 1: Build [duration: 30 seconds]
│ └── Step 2: Deploy [duration: 21 seconds]
├── Stage 3: Backends [duration: 4 minutes and 42 seconds]
│ ├── DB Sync Cron [duration: 1 minute and 42 seconds]
│ │ ├── Step 1: Build [duration: 22 seconds]
│ │ └── Step 2: Deploy [duration: 10 seconds]
│ ├── Core Backend [duration: 4 minutes and 37 seconds]
│ │ ├── Step 1: Build [duration: 1 minute and 12 seconds]
│ │ ├── Step 2: Deploy [duration: 3 minutes and 18 seconds]
│ │ └── Step 3: Deployed [duration: 2 minutes and 21 seconds]
│ ├── Lambda [duration: 4 minutes and 23 seconds]
│ │ ├── Step 1: Build [duration: 1 minute and 2 seconds]
│ │ └── Step 2: Deploy [duration: 2 minutes and 46 seconds]
│ └── Backend [duration: 4 minutes and 37 seconds]
│ ├── Step 1: Build [duration: 1 minute and 15 seconds]
│ ├── Step 2: Deploy [duration: 3 minutes and 18 seconds]
│ └── Step 3: Deployed [duration: 1 minute and 52 seconds]
├── Stage 4: Gateways [duration: 53 seconds]
│ └── API Gateway [duration: 50 seconds]
│ ├── Step 1: Build [duration: 22 seconds]
│ ├── Step 2: Deploy [duration: 25 seconds]
│ └── Step 3: Deployed [duration: 9 seconds]
└── Stage 5: Frontends [duration: 2 minutes and 18 seconds]
├── Frontend [duration: 2 minutes and 13 seconds]
│ ├── Step 1: Build [duration: 1 minute and 16 seconds]
│ └── Step 2: Deploy [duration: 52 seconds]
└── Dashboard [duration: 0 seconds]
└── Step 1: Deploy \[duration: 0 seconds\]
In my context, the most expensive operation (almost 5 minutes..) is the Deploy from my Terraform RDS service inside my 1st stage Databases. In this example, I can't optimize the Terraform RDS since it takes time for AWS to spin up the resource. So independent from my end. However, I see a bunch of Build and Deploy steps that could be optimized.
Here are the most important elements to improve your deployment time performance.
Optimizing your Dockerfile is like fine-tuning an engine for maximum performance. Start by using a lightweight base image - think of Alpine for Node.js applications. For instance:
FROM node:20-alpine
Multi-stage builds can further slim down your final image by keeping only what's necessary for runtime.
FROM node:20-alpine AS builder
WORKDIR /build
RUN --mount=type=ssh yarn install
FROM node:20-alpine
WORKDIR /app
COPY --from=builder /build/node_modules ./node_modules
...
Be strategic with layer caching. Cache your project’s dependencies, which seldom change, before the application code, ensuring faster builds.
Read more about Dockerfile optimization.
The traditional way of deploying applications often includes building the entire stack from scratch. While this gives you control, it's often time-consuming. Utilizing a pre-built image can dramatically speed up your build time because the foundation is already laid out. Here's how.
Traditional Node.js Dockerfile:
FROM node:14 AS build
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
RUN npm run build
# Production image
FROM node:14
WORKDIR /app
COPY --from=build /app/dist /app
CMD ["npm", "start"]
Using a Pre-built Container Image:
Assume you have a pre-built image prebuilt-node-image that already contains your node_modules and other dependencies.
FROM prebuilt-node-image
WORKDIR /app
COPY . .
CMD ["npm", "start"]
The second approach eliminates the need to download and install Node packages each time, saving you precious minutes or even hours, depending on your application's complexity.
Think of your build process as a production line. The efficiency of this line determines how fast your product - your application - gets to market. While Qovery provides highly optimized builders with 4 vCPUs and 8GB of RAM for each build and supports up to four builders running in parallel, there could be scenarios where you might need additional speed. This is where tools like Depot come in handy.
Depot caches your build artifacts, ensuring that repeated builds get faster over time. It's like adding another layer of efficiency to an already optimized assembly line. So, while Qovery's builders are robust and capable, you have the option to employ Depot for that extra dash of speed.
When it comes to speeding up frontend builds, Nx is like your turbocharger. By using computation caching and parallel task execution, Nx significantly reduces build times, especially in monorepo settings where you have multiple frontend applications.
Read more about why the Qovery Frontend team uses Nx
In a sprawling monorepo, it's inefficient to rebuild and redeploy every app for every minor change. Use Qovery deployment restrictions to act like a smart sensor, triggering builds only for the apps that have changed, thereby preventing unnecessary builds.
Choosing the right amount of CPU and RAM for your app is like setting the correct tire pressure on a race car. Too low and you compromise speed; too high and you risk a blowout. Adjusting these settings appropriately ensures that your applications start faster and run smoother.
Building at runtime, especially for Server-Side Rendering (SSR) apps, is like assembling furniture when you're trying to move into a new apartment - it's not the time nor the place. This approach increases latency and strains system resources. Always opt to pre-build your SSR applications to achieve faster and more stable deployments.
Choosing the "Recreate" deployment strategy is akin to using a sledgehammer when you're in a rush; it's forceful but effective. This strategy stops the old application instances and immediately spins up the new ones, cutting the waiting time dramatically. However, use it cautiously; it's ideal for test environments but not recommended for production.
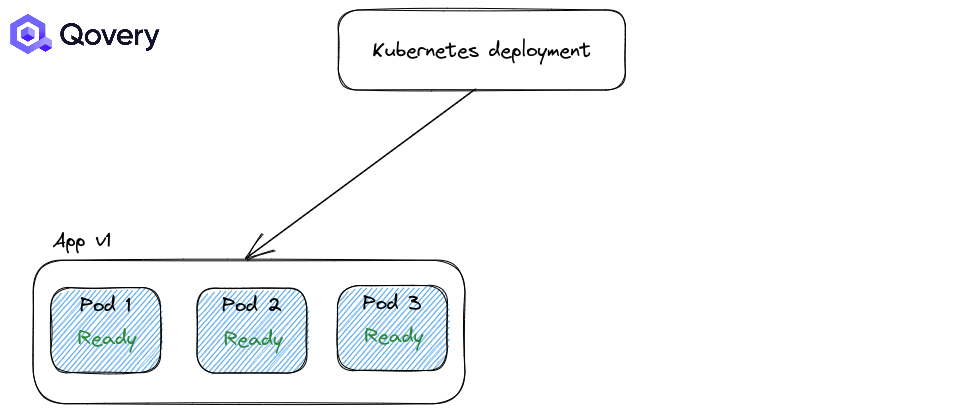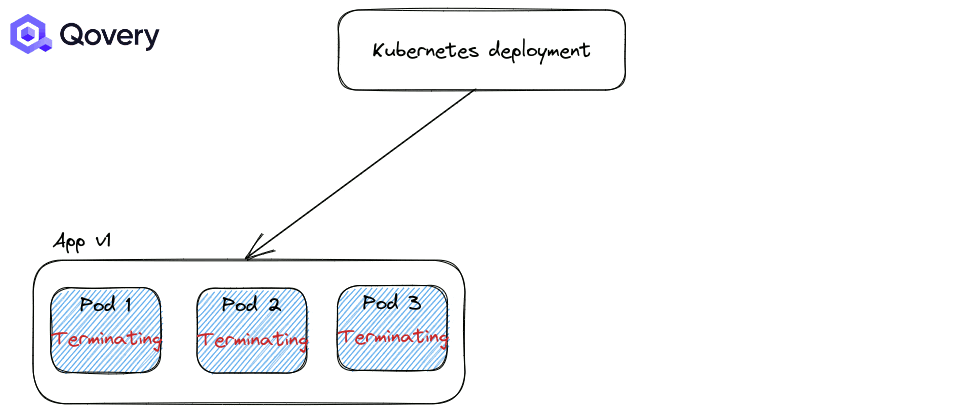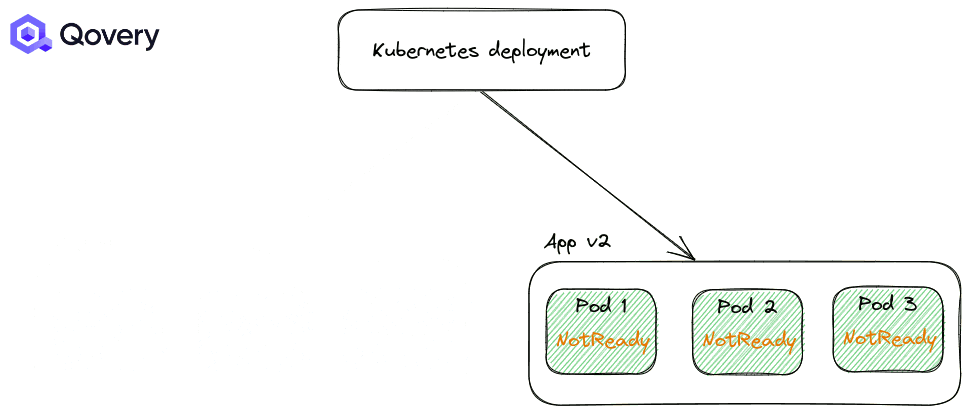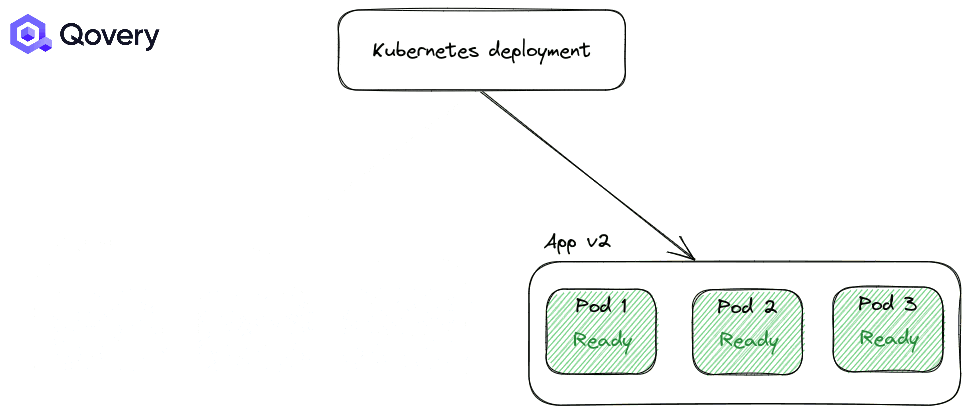
Configuring efficient health checks is like having a well-trained medical team at a sports event. They quickly assess the situation and make informed decisions, allowing for smooth and fast transitions. Proper health checks enable quicker deployments and offer better resilience against failures.
To learn more about Health Checks and Probes - read this article .
Finally, never underestimate the power of constant vigilance. Monitoring your application is like having a seasoned coach who can spot even the tiniest inefficiencies and recommend immediate improvements. Consistent monitoring of system performance allows you to proactively optimize your settings, ensuring that future deployments are faster and more efficient.
Reducing deployment time is an ongoing process that involves both platform and user-side optimizations. While Qovery automates many tasks to make deployments faster, the strategies outlined above will help you make your pipeline even more efficient. So go ahead, implement these practices and shave off those valuable seconds or even minutes from your deployment time.
Happy Deploying!
Romaric founded Qovery to make Kubernetes accessible to every engineering team. He writes about platform strategy, developer experience, and the future of cloud infrastructure.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.