Best Practices for Web Application Deployment: The Zero-Downtime Strategy
Web App Deployment Best Practices: Achieve frequent, safe releases with this guide. Learn about Rolling Updates for zero downtime, CI/CD automation, the essential deployment checklist, and creating a reliable rollback strategy.
Prioritize Zero-Downtime Deployment: The foundational strategy must be Rolling Updates, which staggers deployment across phases or components. This ensures zero downtime, limits the impact of bugs to a fraction of users (good fault tolerance), and simplifies rollbacks.
Automate Everything (CI/CD and Testing): Frequent deployments are only possible through Continuous Integration (CI) and Continuous Deployment (CD). This automation must be complemented by extensive automated testing (beyond unit tests) and a comprehensive deployment checklist to verify database scripts, environment variables, and third-party integrations.
Establish a Safety Net (Monitoring & Rollback): Deployment safety requires a reliable tested rollback strategy that maintains the last two successful releases and can handle database script reversals. This must be coupled with continuous monitoring and immediate notification alerts to quickly detect and inform stakeholders of any new issues or regressions post-deployment.
Is Your "Fast" Deployment Strategy a Hidden Liability?
The pressure to release features quickly is high, but if your deployment strategy can't support the pace, you risk a catastrophic production failure. Firing off frequent releases without the right expertise and tools will inevitably lead to downtime and severe negative business impact.
This guide cuts through the noise and provides the non-negotiable best practices - from embracing zero-downtime updates to establishing air-tight rollback protocols - ensuring your team can deploy on any scale frequently, safely, and correctly.
Use Rolling Updates
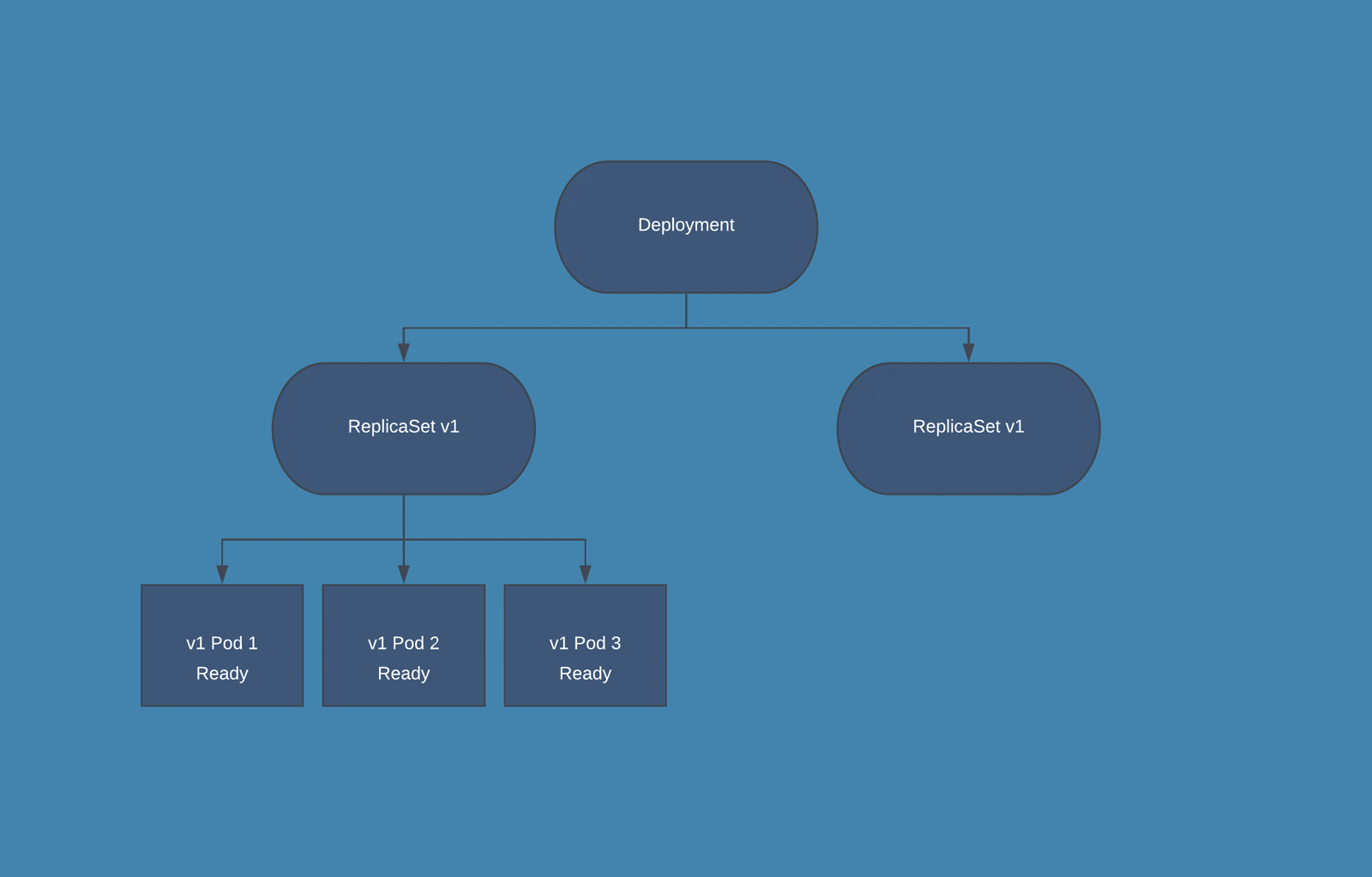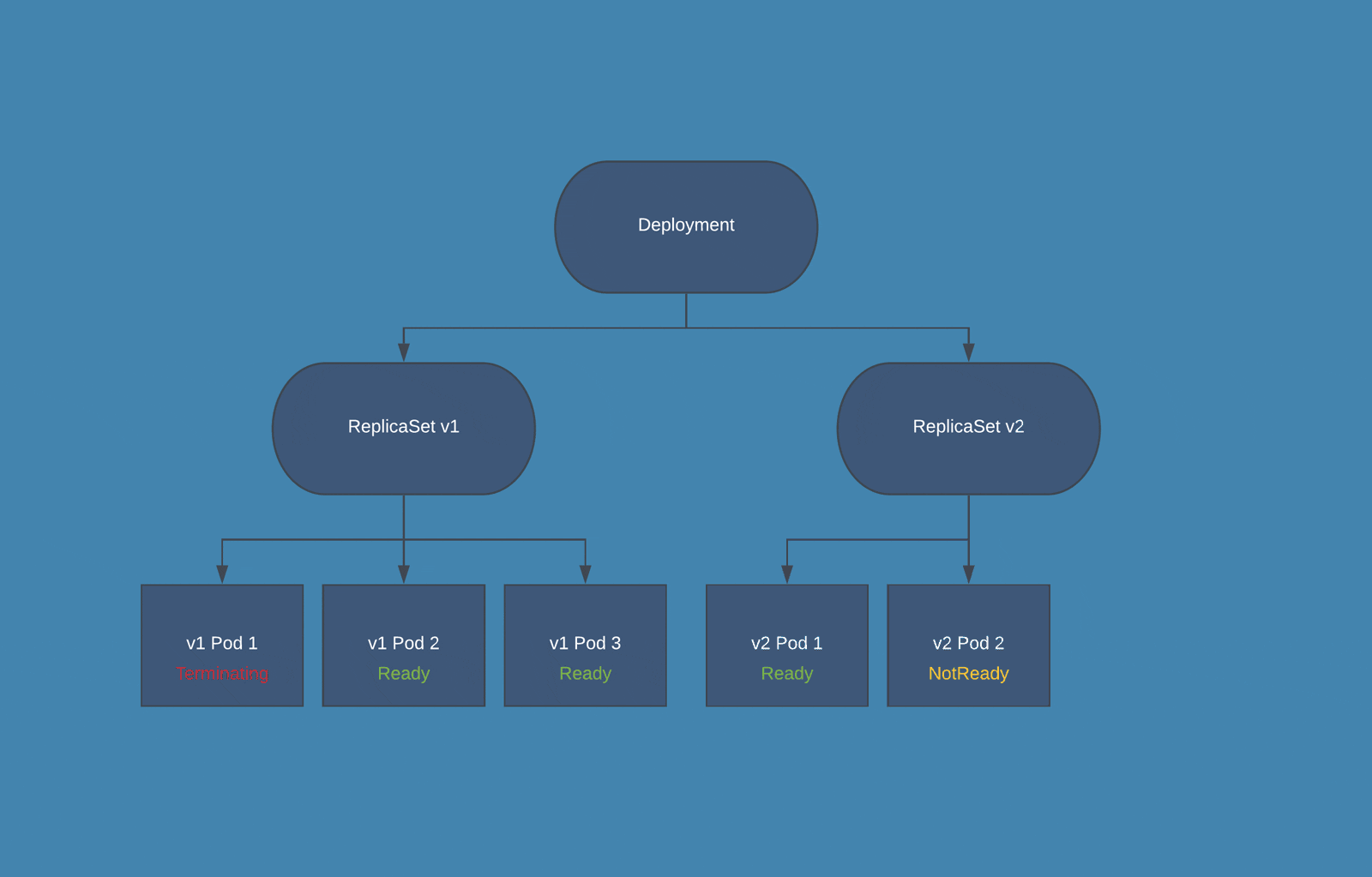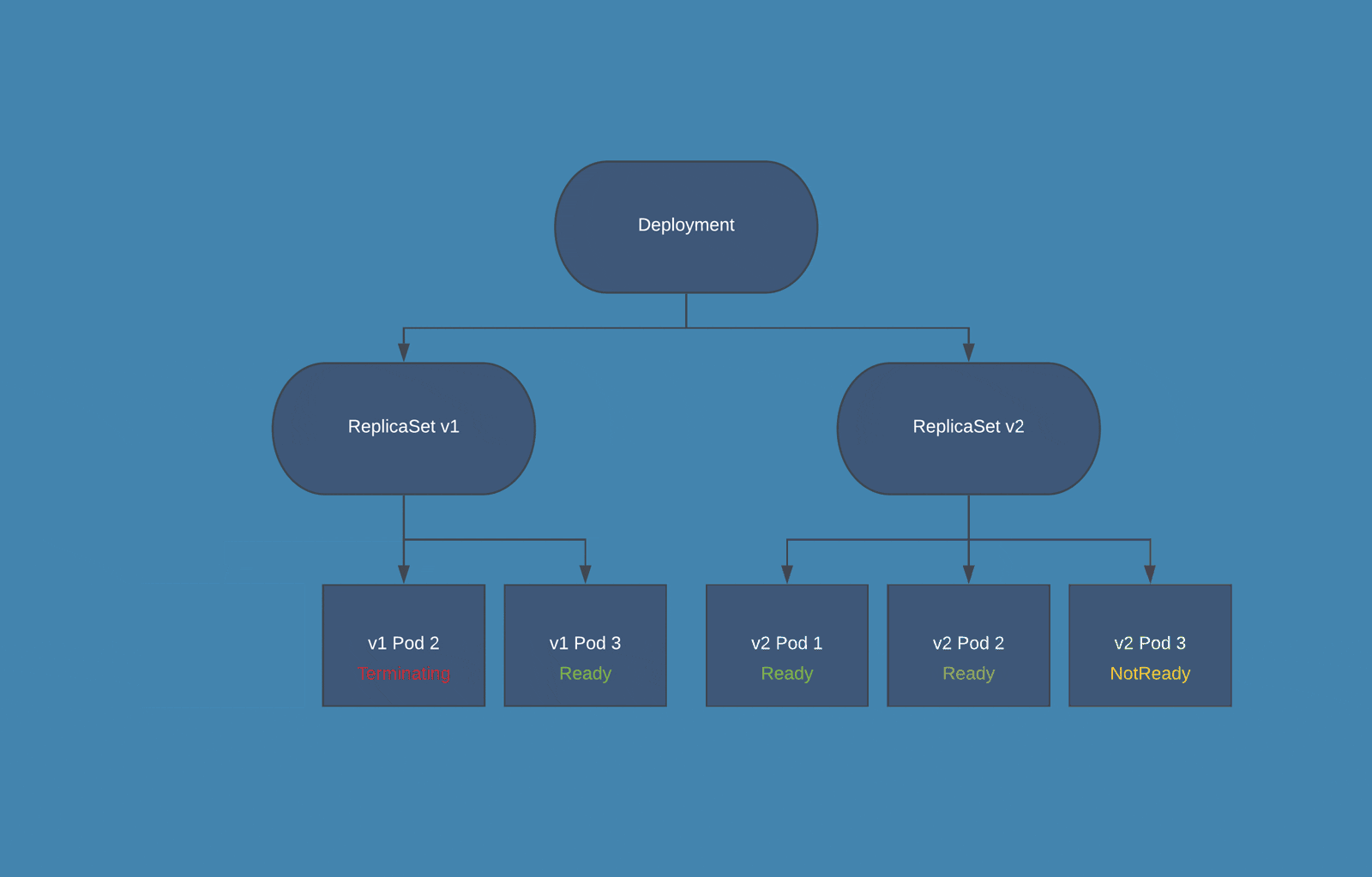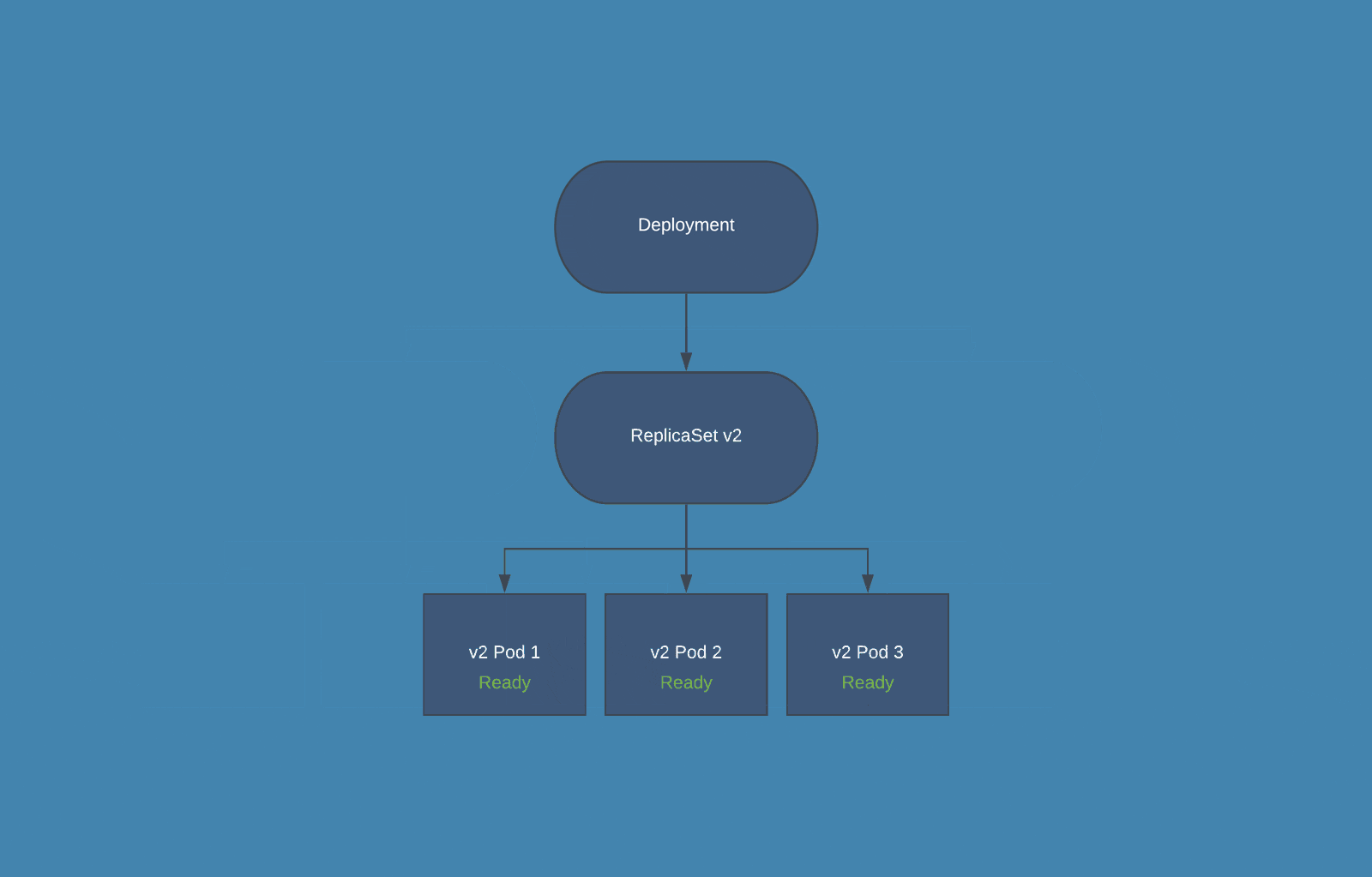
Rolling update is a deployment strategy that ensures zero downtime. It staggers deployment across multiple phases instead of one big burst. You can deploy to only one of the servers simultaneously instead of deploying to all the servers on one go. It can also be applied to only deploying one of the components instead of replacing all the old components in one go. It is a great fit for applications that can have multiple instances/components running concurrently with different versions.
Kubernetes Rolling Updates - Source: bluematador.com
Some of the advantages of rolling updates include the following:
No Huge Bursts. As the deployment is performed in phases instead of one big burst, you can easily find deployment issues in a particular component or server. It does not increase the load on infrastructure and is cost-effective.
Good Fault Tolerance. Any bugs or instability in your new node/component will affect only a fraction of your users. Modern deployment tools even support rolling updates deployment that can let you keep all old nodes connected and divert only a small amount of traffic to a new node during the testing stage. That brings in good fault tolerance.
Rollback is Easy. As the old components or nodes are not retired, you can roll the changers back quickly. Rolling back is as simple as reverting the traffic redirect. Even if the failure is detected much further into the deployment process, advanced tools can automatically roll the changes back by adding new instances of old nodes/components.
There are some cases where rolling updates might not be the best choice. Here are some of those:
Not suitable for stateful applications. Although most modern web applications are stateless, for some legacy stateful applications, transient information stored in the instance (sessions, cached files, etc.) might be lost when an instance is updated or replaced.
One of the challenges with rolling updates is supporting two versions of the application running simultaneously. The new version should be implemented not to break the old version. It is important to consider both backward and forward compatibility.
Rolling Updates is the simplest of all the deployment techniques and should be the first one to be adopted for zero-downtime deployments. Using AWS CodePipeline, AWS CodeDeploy or solutions like Qovery facilitate rolling updates deployments.
Bring in Automation
Automating the deployments is becoming inevitable in modern application development. Gone are the days when you used to deploy a release after a month or two. Now many big tech companies deploy hundreds of times each day, and the reason they can do this seamlessly is the adoption of CI/CD.
Continuous Integration (CI) and Continuous Deployment (CD) are an integral part of your software development if you want to scale your deployments. Continuous Integration makes sure that code is checked frequently, at least once a day. That way, you can find and fix code breakage early. Continuous Deployment allows you to deploy multiple times a day quickly without introducing any errors.
If a regression bug is introduced as a result of production deployment, it can be converted into failure. So one should set up not only monitoring on the application performance but immediate notifications should be set up to inform of any issues at once. Several tools are available for application monitoring and alerts that give many metrics related to applications, support, analytics, etc.
Some of the top tools for performance monitoring and notifications include Datadog, New Relic, etc. They offer the ability to see inside any technology stack or application at any scale and are equipped with Infrastructure monitoring, APM, log management, server monitoring, cloud workload monitoring, database monitoring, etc.
Cloud monitoring with Datadog
Agents ship fast. Guardrails keep them safe.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.
Did you ever wonder; how big corporations ensure the health of applications after making thousands of deployments on any given day? The answer is automated testing. There are large sets of automated tests on every deployment, which verify if any part of the application is not working correctly. The deployment is rolled back automatically with zero downtime if any issue is detected.
That does not mean that unit tests and integration tests are less important. They have their own place in ensuring code quality and smooth functioning of the application. Automation tests complement unit/integration tests, and it does not replace them.
Automation of load/stress testing is also important, especially for large applications. Manually running stress tests might be effective for small applications, but automation is necessary when application scales.
AWS provides DeviceFarm to facilitate automated testing. Some other tools include Selenium, Katalon, etc.
The Essential Deployment Verification Checklist
Another common and very effective practice on efficient deployment is maintaining a good checklist of deployment-related tasks.
Some of the core items of this checklist include the following:
Check database scripts have been executed correctly
Create a rollback plan
Release notes are ready (features being shipped, missed features, open bugs, etc.)
Build passes all units and integration tests
Automated tests are passed
Environment variables are correctly managed. API keys, secrets, etc. are all properly maintained.
Monitor logs to keep an eye on application and server health
Check 3rd party integrations are working
Deployment was run first on the staging server with success.
Rollback strategy
Every successful deployment supports a rollback strategy. And not just any rollback strategy but a reliable and tested rollback strategy. Here are some of the critical points which must be part of any rollback strategy:
Document your rollback strategy
Test your rollback strategy by simulating deployment issues
Always maintain the last two successful releases in every environment. Take the example of AWS CodeDeploy. It rollbacks to the last known good version of the application if a deployment fails.
Make sure the deployment tool supports rollback of database scripts as well.
If your deployment tool has been configured the build rollback based on automated test case failure, it is advised to approve the rollback only if necessary. Sometimes, a test case is failed due to a known issue acceptable to business, in which case you can forgive the error and forward the deployment instead of rollback.
Setup monitoring even after the rollback to ensure successful rollback to a stable version.
Set up email/SMS notifications in case of successful rollback
It takes some practice to be fully adept at your deployments. The best-case scenario for software deployments is that it becomes a routine, uneventful task for your team. It should not get in the way of all the hard development work of you and your team.
By developing the right process, choosing the right tools, and automating as much as possible, you can make your deployments efficient and simple.
Morgan co-founded Qovery and leads engineering. He writes about Kubernetes architecture, DevOps best practices, and building resilient infrastructure at scale.
Next step
Agents ship fast. Guardrails keep them safe.
Qovery ensures every agent action is scoped, audited, and policy-checked. Start deploying in under 10 minutes.