Scaling Kubernetes on AWS: Everything You Need to Know
Kubernetes has emerged as the go-to platform for container orchestration, empowering organizations to efficiently deploy and manage applications at scale. As the demands on applications continue to grow, scaling Kubernetes becomes essential to ensure high availability, optimal performance, and seamless expansion. Today, we will delve into the intricacies of scaling Kubernetes on AWS, exploring best practices, popular tools, performance optimization strategies, cost considerations, and future trends. By understanding the nuances of scaling Kubernetes on AWS, you can effectively meet your business needs and unleash the full potential of this powerful combination.

Morgan Perry
June 18, 2023 · 12 min read
Morgan Perry
Co-founder of Qovery. Morgan is a Tech entrepreneur with 10 years of experience in the SaaS industry.
See all articles#Understanding Kubernetes Scaling
Scaling is a fundamental concept in Kubernetes that allows organizations to meet the increasing demands of their applications while maintaining high availability and optimal performance. In this section, we will explore the intricacies of Kubernetes scaling, including its significance, the two types of scaling—horizontal and vertical, the benefits it offers, and the challenges that engineering teams may encounter.
#The Concept of Scaling in Kubernetes
Scaling in Kubernetes refers to the ability to dynamically adjust the resources allocated to your application workloads based on demand. It involves adding or removing resources such as pods, nodes, or containers to match the changing needs of your applications. By scaling effectively, you can ensure that your applications have the necessary resources to handle increased traffic, maintain responsiveness, and deliver a seamless user experience.
#Horizontal Scaling and Vertical Scaling
In Kubernetes, there are two primary approaches to scaling: horizontal scaling and vertical scaling.
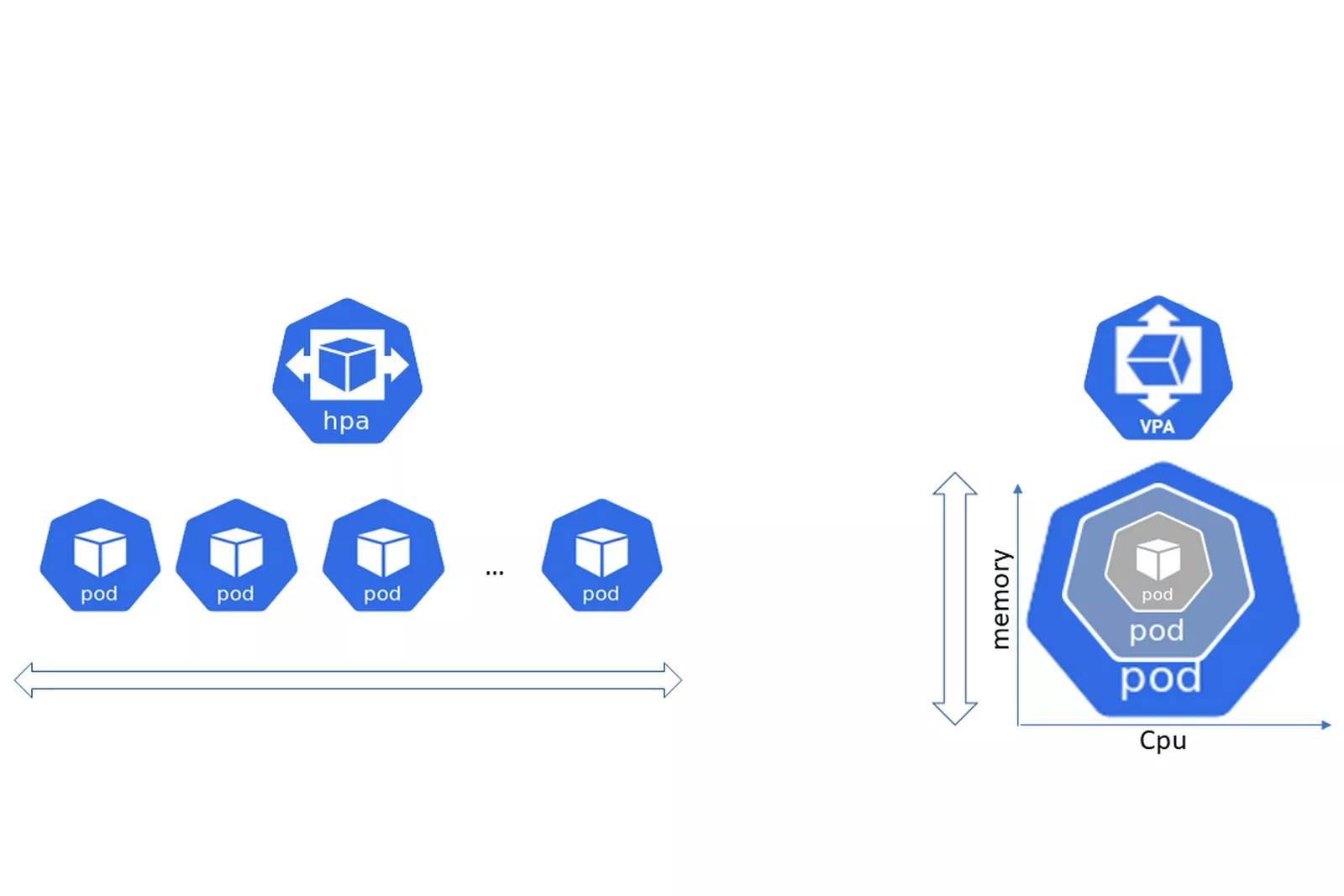
Horizontal Scaling Horizontal scaling, also known as scaling out, involves adding more instances of application components, such as pods or containers, to distribute the workload across multiple nodes. By horizontally scaling your application, you can handle increased traffic and achieve better load balancing. This approach enhances fault tolerance and allows you to scale your application horizontally by adding or removing instances as needed.
Vertical Scaling Vertical scaling, also known as scaling up or down, involves adjusting the resources allocated to individual instances of your application components. It typically involves increasing or decreasing the CPU, memory, or storage capacity of a single instance. Vertical scaling allows you to handle increased workload by providing more resources to a specific component, but it may have limitations in terms of the maximum capacity of a single instance.
#Benefits of Scaling Kubernetes
Scaling Kubernetes offers several notable benefits for organizations:
- Efficient Resource Utilization: Scaling Kubernetes allows for optimal resource utilization by dynamically allocating resources based on application demand. It enables you to maximize the utilization of infrastructure resources such as CPU, memory, and storage, ensuring efficient utilization across your cluster.
- Enhanced Fault Tolerance: Scaling Kubernetes improves the fault tolerance of your applications. By distributing workloads across multiple nodes or instances, it reduces the risk of single points of failure. If one node or instance fails, the workload can be automatically shifted to other healthy nodes, ensuring the availability of your applications.
- Improved Load Balancing: Kubernetes scaling enables effective load balancing by distributing incoming traffic across multiple instances or pods. This helps to evenly distribute the workload and prevent any single instance from becoming overwhelmed. With load balancing, you can ensure that your applications can handle high traffic volumes and deliver consistent performance.
- Elasticity and Flexibility: Kubernetes scaling provides elasticity and flexibility to adapt to changing workloads. You can scale your applications up or down based on demand, allowing you to seamlessly handle traffic spikes during peak periods and scale back resources during quieter periods. This elasticity enables cost optimization and ensures that resources are allocated efficiently.
- Seamless Application Updates: Scaling Kubernetes simplifies the process of rolling out updates or deploying new versions of applications. By scaling up new instances or pods while gradually scaling down the old ones, you can ensure zero-downtime updates and smooth transitions between versions. This helps to maintain continuous application availability and reduces the impact on end users.
- Simplified Management and Operations: Kubernetes scaling provides centralized management and control of your application infrastructure. Instead of individually managing and scaling each component, you can use Kubernetes primitives to define desired states and let the platform handle the orchestration. This simplifies operations and reduces the administrative overhead of managing complex application architectures.
- Scalability Across Clusters: Kubernetes scaling allows you to scale across multiple clusters, enabling you to distribute workloads across different regions or availability zones. This provides geographical redundancy, improves performance for users in different locations, and ensures high availability even in the event of infrastructure failures in a specific region.
- Increased Developer Productivity: By automating the scaling process, Kubernetes allows developers to focus more on application development and less on infrastructure management. The self-service nature of Kubernetes scaling empowers developers to quickly scale their applications as needed, reducing the time and effort spent on manual scaling operations.
#Challenges of Scaling Kubernetes
While scaling Kubernetes brings significant advantages, organizations may face certain challenges during the process:
- Complexity and Learning Curve Scaling Kubernetes requires a deep understanding of its architecture, concepts, and various scaling mechanisms. Engineering teams need to invest time and effort into learning Kubernetes scaling best practices and tools to ensure a smooth and successful scaling experience.
- Resource Allocation and Management Efficiently allocating and managing resources during scaling operations can be complex. Engineering teams need to carefully monitor resource usage, consider cluster capacity, and implement appropriate scaling strategies to avoid overprovisioning or underutilization of resources.
- Application Compatibility and Dependencies Scaling applications in Kubernetes may involve managing dependencies, ensuring application compatibility with scaled environments, and handling any potential issues that arise during the scaling process. This requires thorough testing, version compatibility checks, and effective coordination between development and operations teams.
#Tools and Solutions for Scaling Kubernetes on AWS
When deciding which Kubernetes solution to select, we come across many options, including Rancher, Amazon Elastic Kubernetes Service (EKS), self-hosted Kubernetes, Kops, Kubeadm, and Qovery. Each solution offers its own set of features and considerations, allowing users to select the option that best meets their Kubernetes deployment requirements on the AWS platform. In a previous article, we discussed all these solutions in detail that helps you decide on the right Kubernetes tool for your needs.
Choosing the Best Options to Run Kubernetes on AWS
#Optimizing Kubernetes Performance During Scaling
Scaling Kubernetes is not just about adding more resources; it also requires optimizing the performance of your clusters to ensure efficient utilization of resources and maintain optimal application performance. In the following, we will explore the importance of performance optimization during scaling operations and discuss strategies to achieve optimal Kubernetes performance on AWS.
#Importance of Performance Optimization during Scaling Operations
When scaling Kubernetes on AWS, it's crucial to consider performance optimization to ensure your applications can handle increased workloads effectively. Performance optimization helps maximize resource utilization, improve response times, and enhance overall system efficiency. By optimizing performance during scaling operations, you can avoid potential bottlenecks, reduce costs, and deliver a seamless user experience.
#Strategies for Optimizing Kubernetes Performance on AWS
- Leveraging AWS Auto Scaling Groups AWS Auto Scaling Groups provide a powerful mechanism to automatically adjust the number of instances in your Kubernetes clusters based on workload demands. By configuring appropriate scaling policies and utilizing features such as target tracking scaling, scheduled scaling, and dynamic scaling, you can dynamically scale your clusters in response to changing workloads. This ensures that your clusters have the right amount of resources at all times, optimizing performance and cost efficiency.
- Optimizing Networking Networking plays a critical role in the performance of Kubernetes clusters. Implementing network optimization strategies such as using AWS Elastic Load Balancers to distribute traffic, configuring VPC networking for high throughput and low latency, and utilizing AWS PrivateLink for secure communication between services can significantly improve the performance and reliability of your applications. Additionally, implementing network policies and traffic routing mechanisms within your Kubernetes clusters can further enhance performance and security.
#Best Practices for Monitoring and Fine-Tuning Performance
To maintain optimal performance in scaled Kubernetes clusters, it's essential to monitor and fine-tune various aspects of your infrastructure and applications. Some best practices include:
- Implementing comprehensive monitoring and observability solutions to gain insights into the performance and health of your Kubernetes clusters. Tools like Datadog, Prometheus, Grafana, and AWS CloudWatch provide valuable metrics and alerts that enable proactive performance management.
- Regularly reviewing and optimizing resource allocation, such as CPU and memory limits, to ensure efficient utilization and avoid resource contention.
- Analyzing application performance and identifying potential bottlenecks through profiling and tracing tools like Jaeger and OpenTelemetry.
- Conducting load testing and performance testing to simulate real-world scenarios and identify performance limitations early on.
- Continuously optimizing application code, configurations, and container images to improve efficiency and reduce resource consumption.
By following these basics, you can ensure that your scaled Kubernetes clusters on AWS operate at their peak performance and deliver an exceptional user experience.
#Cost Considerations
Scaling Kubernetes on AWS brings not only technical considerations but also financial implications. Understanding the cost factors and implementing cost optimization strategies is crucial to ensure the scalability of your infrastructure without breaking the bank. In this section, we will discuss the cost implications of scaling Kubernetes on AWS, explain the pricing models and factors that impact the cost of running scaled Kubernetes clusters, and provide cost optimization tips to minimize expenses.
#Cost Implications of Scaling Kubernetes on AWS
When scaling Kubernetes on AWS, several cost factors come into play. These include:
- Compute Resources: The primary cost component is the compute resources required to run your Kubernetes clusters. This includes the cost of EC2 instances, storage volumes, and networking resources. As you scale your clusters, the number of instances and the type of instances you utilize will directly impact your costs.
- Data Transfer: Data transfer costs can accumulate when scaling Kubernetes, especially if your applications generate significant outbound network traffic or communicate with external services. AWS charges for data transfer between regions, availability zones, and out to the internet.
- Load Balancing and Networking: Using load balancers and networking services such as AWS Elastic Load Balancers and AWS PrivateLink incurs additional costs. It's important to consider the number of load balancers, the amount of data transferred, and any additional networking features required for your workload.
- Management and Monitoring: Managing and monitoring your scaled Kubernetes clusters may involve costs associated with tools and services used for monitoring, logging, and tracing. AWS provides services like CloudWatch and CloudTrail, which have associated pricing based on usage.
- Support and Reserved Instances: Opting for AWS support plans or utilizing Reserved Instances can also impact your overall costs. Depending on your requirements and budget, you may choose different support tiers or reserve instances to reduce costs in the long run.
#Pricing Models and Factors Affecting Cost
Understanding the pricing models and factors that impact the cost of running scaled Kubernetes clusters is essential. Key factors to consider include:
- EC2 Instance Type and Size: Different EC2 instance types have varying pricing structures. Factors such as CPU, memory, and storage capacity contribute to the overall cost.
- Storage: The type and size of storage volumes, such as Amazon EBS or Amazon S3, can affect costs. Provisioned IOPS or increased storage capacity may incur additional charges.
- Data Transfer: Costs associated with inbound and outbound data transfer between services, regions, and the Internet should be considered.
- Load Balancers and Networking: The number of load balancers and data transferred through them can impact costs. Additionally, using advanced networking features may have associated charges.
- Additional Services: Usage of additional AWS services, such as CloudWatch, CloudTrail, or AWS Identity and Access Management (IAM), may incur costs.
#Cost Optimization Tips
To minimize expenses while scaling Kubernetes on AWS, consider the following cost optimization tips:
- Rightsizing Instances: Regularly evaluate the resource requirements of your applications and adjust the instance types and sizes accordingly. Rightsizing instances can help eliminate overprovisioning and optimize costs.
- Using Spot Instances: Take advantage of AWS Spot Instances, which offer significant cost savings compared to On-Demand Instances. Spot Instances allow you to bid on spare EC2 capacity and can be a cost-effective option for non-critical workloads or those with flexible resource requirements.
- Automation and Autoscaling: Implement automation and autoscaling to dynamically adjust the number of instances based on workload demands. This ensures optimal resource utilization and cost efficiency.
- Resource Tagging and Allocation Tracking: Use resource tagging and allocation tracking to gain visibility into cost distribution across your Kubernetes clusters. This helps identify areas of high spending and optimize resource allocation.
- Reserved Instances: Evaluate the utilization patterns of your Kubernetes clusters and consider purchasing Reserved Instances for long-term workload stability. Reserved Instances offer discounted pricing for committed usage over a specific term.
- Cloud Cost Management Tools: Leverage cloud cost management tools like Usage.ai, Kubecost, or tools provided by AWS, such as AWS Cost Explorer, to gain insights into your spending and set up cost controls.
#Future Trends and Considerations
The landscape of Kubernetes is ever-evolving. New trends and emerging technologies are shaping the way we scale Kubernetes on AWS. Staying updated with these advancements and considering future considerations is crucial for optimizing your infrastructure and maximizing the benefits of Kubernetes. Let’s explore some of the future trends and considerations related to scaling Kubernetes on AWS.
#Multi-cluster Management
With the increasing adoption of Kubernetes, managing multiple clusters efficiently becomes essential. Multi-cluster management solutions, such as Kubernetes Federation or Kubernetes Operators, enable centralized management and coordination of multiple clusters. These solutions simplify tasks like application deployment, scaling, and resource management across clusters. Exploring and implementing such solutions can enhance scalability and operational efficiency in a multi-cluster environment.
Leveraging the right tools can further streamline multi-cluster management. Tools like Qovery offers advanced features for multi-cluster management, allowing you to scale and manage your Kubernetes environments across multiple clusters efficiently.
Here’s a customer success story highlighting the benefits of Qovery in multi-cluster management, where Spayr, a fintech company, shared their experience of successfully managing multiple environments on Kubernetes using Qovery. They were able to streamline their deployment processes, achieve better scalability, and ensure high availability across multiple clusters. You can read the full success story here.
By utilizing solutions like Qovery, you can simplify and optimize your multi-cluster management, enabling seamless scalability and efficient resource utilization across your Kubernetes environments.
#Hybrid Cloud Deployments
Many organizations are adopting hybrid cloud strategies, combining on-premises infrastructure with the public cloud. Kubernetes plays a crucial role in enabling seamless workload portability across hybrid environments. Technologies like AWS Outposts or AWS Hybrid Networking allow you to extend your Kubernetes clusters to on-premises infrastructure. By leveraging these technologies, you can scale Kubernetes workloads across hybrid environments while maintaining consistency and control.
#Serverless Architectures
Serverless computing, represented by AWS Lambda, provides an event-driven execution environment where you only pay for the actual usage of your code. Integrating serverless architectures with Kubernetes brings additional benefits, such as automatic scaling, reduced operational overhead, and cost optimization. Technologies like Knative or AWS Fargate allow you to run serverless workloads on Kubernetes, enabling efficient scaling and cost-effective execution. Exploring serverless architectures in conjunction with Kubernetes can unlock new possibilities for scaling and resource utilization.
#Conclusion
Scaling Kubernetes on AWS is a critical aspect of modern application deployment. By understanding the importance of scaling, adopting best practices, leveraging tools and solutions, optimizing performance, considering cost implications, and staying informed about future trends, you can successfully scale your Kubernetes clusters on AWS. Aligning your scaling strategies with business needs ensures optimal performance, high availability, and cost-effectiveness. Embrace the power of Kubernetes, unlock its full potential, and embark on a scalable and resilient application journey.
To experience first-hand the power of Qovery's platform, start a 14-day free trial. Sign–up here - no credit card required!
Your Favorite DevOps Automation Platform
Qovery is a DevOps Automation Platform Helping 200+ Organizations To Ship Faster and Eliminate DevOps Hiring Needs
Try it out now!
Your Favorite DevOps Automation Platform
Qovery is a DevOps Automation Platform Helping 200+ Organizations To Ship Faster and Eliminate DevOps Hiring Needs
Try it out now!.jpg?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max)

.jpg?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max)