Implementing Microservices on AWS with the Twelve-factor App – Part 1
The Twelve-Factor methodology is a set of best practices for developing microservices applications. These practices are segregated into twelve different areas of application development. Twelve-factor is the standard architectural pattern to develop SaaS-based modern and scalable cloud applications. It is highly recommended by AWS if you are building containerized microservices.
In this article, we will guide you on how to develop applications that will use microservices deployed on containers in AWS. We will discuss the first six areas today. And in the next article (part 2), we will discuss best practices for the remaining six areas.

Morgan Perry
May 7, 2022 · 6 min read
Morgan Perry
Co-founder of Qovery. Morgan is a Tech entrepreneur with 10 years of experience in the SaaS industry.
See all articles#Codebase
The codebase should be in a code repository, e.g., Git, SVN, etc. Developers should work locally and commit the code to get the code deployed to the server. So it is a single codebase with multiple deploys, e.g., Staging, UAT, Production, etc. The codebase serves as the single source of truth for all the code changes.
Generally speaking, it is recommended to have one codebase per application. However, for microservices-based applications, the recommendation is to have one codebase (or repository) for each microservice.
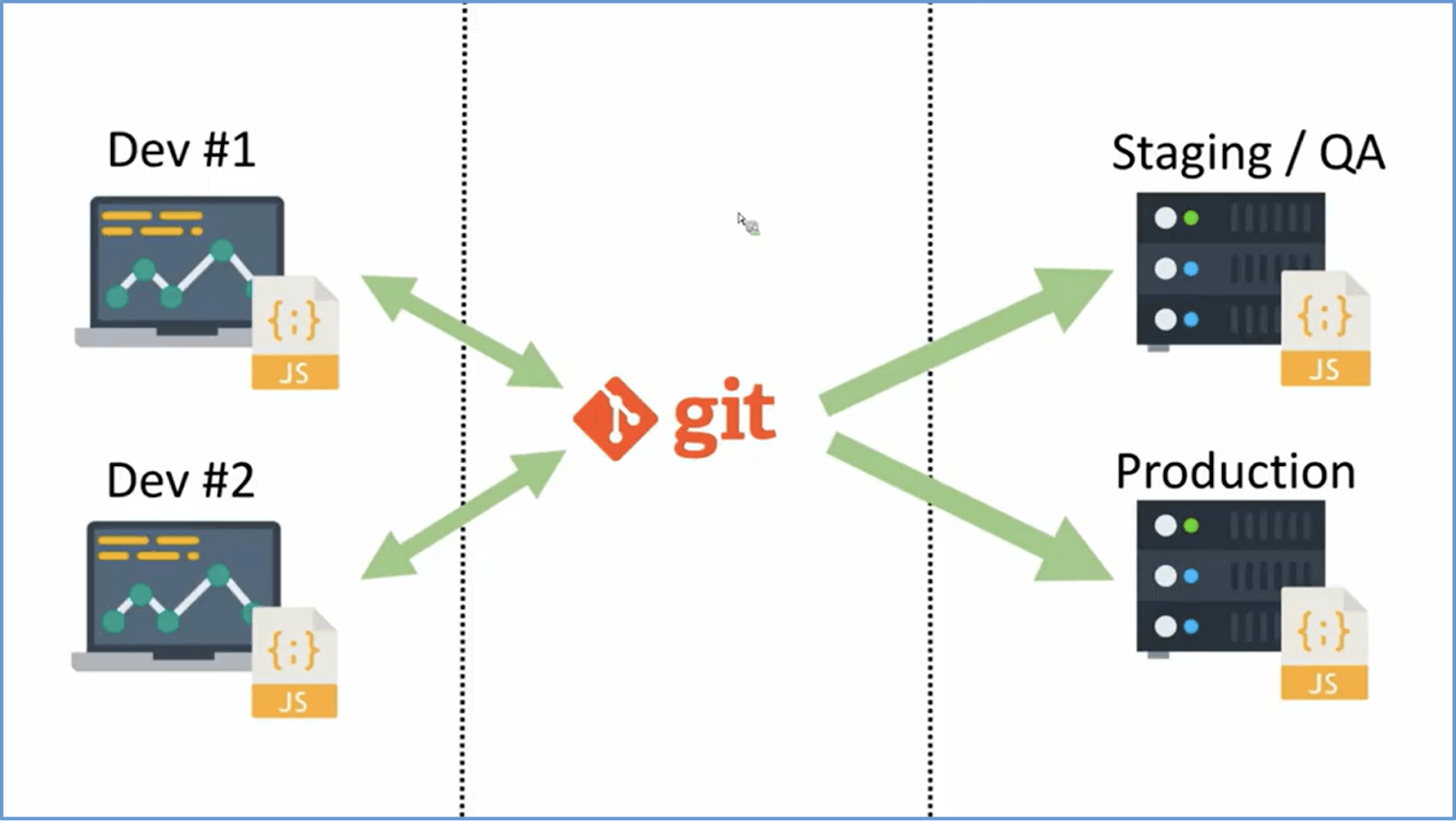
As microservices are usually deployed on containers, so maintaining container images is also an important aspect. It is strongly recommended to have one container image for each containerized application (or microservice), which resides in its own image repository. One example for hosting the private container images is Amazon ECR private repositories.
#Dependency management
Many modern SaaS-based enterprise applications depend on external libraries or packages. The Twelve-factor methodology recommends explicitly declaring and isolating all the dependencies. E.g., if multiple modules use a shared function, then this function should be packaged into a library and included in your deployment package. You should never assume that a dependency will be available on the execution environment, i.e., If you are deploying on an EC2 instance, do not assume that the instance will have the dependency installed. The dependency should be part of your code. Regardless of the platform or programming language, use the dependency manager with whatever development language/framework you are using.
For containerized applications, the go-to choice is the Docker file. A Docker file contains all the commands needed to create the container image. Declare all your application dependencies in the dependency declaration manifest specific to your programming language, and the installation will be done based on the instructions in the docker file. Take the example of python; the two common dependencies are flask and boto3. The package installer of python “Pip” is used to declare these dependencies. Note that dependency declaration and dependency isolation are two different tasks but must be done together.
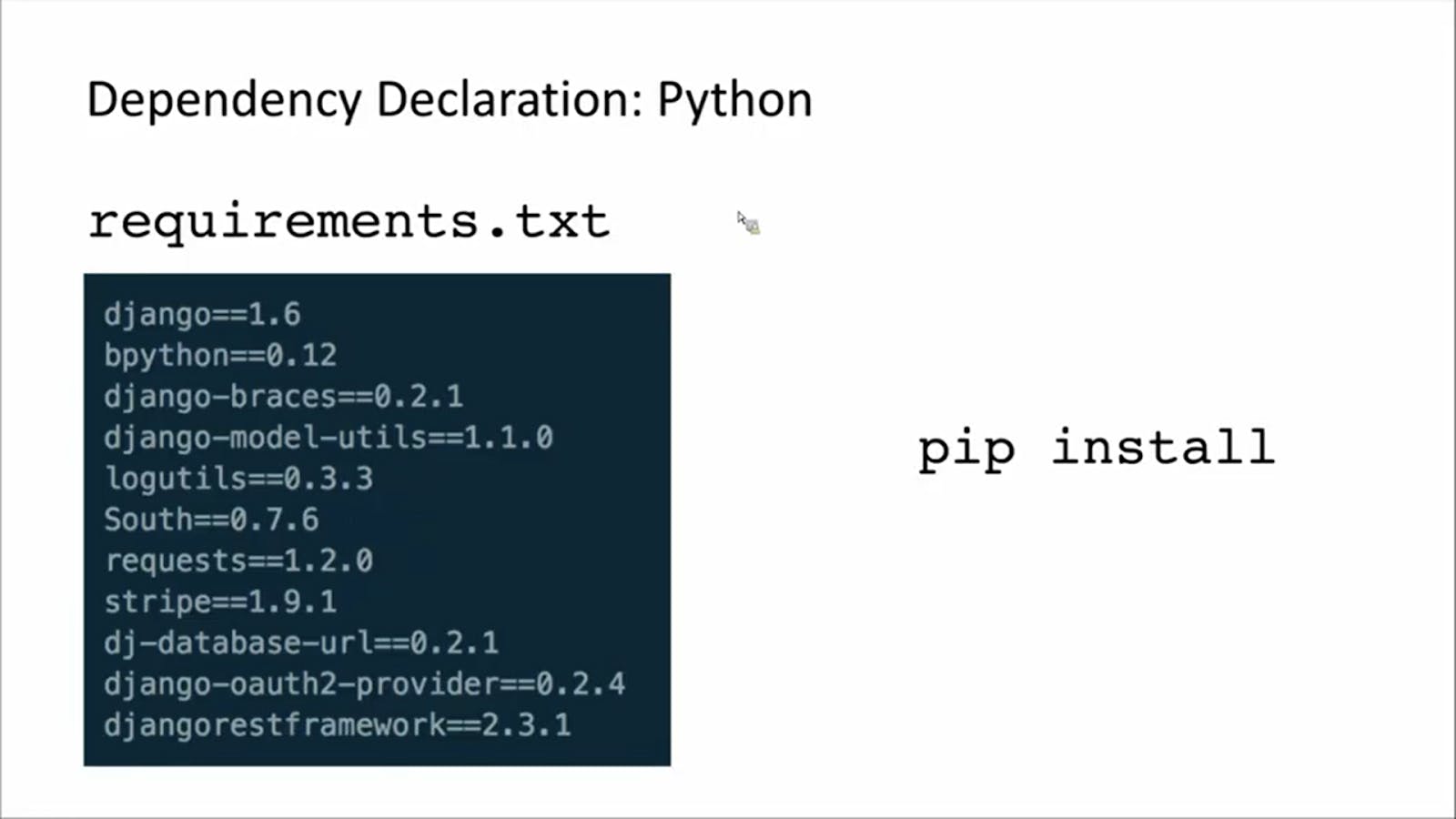
Below is an example of dependency declaration in python. You can see not just the dependency name but also the exact version of the dependencies too.
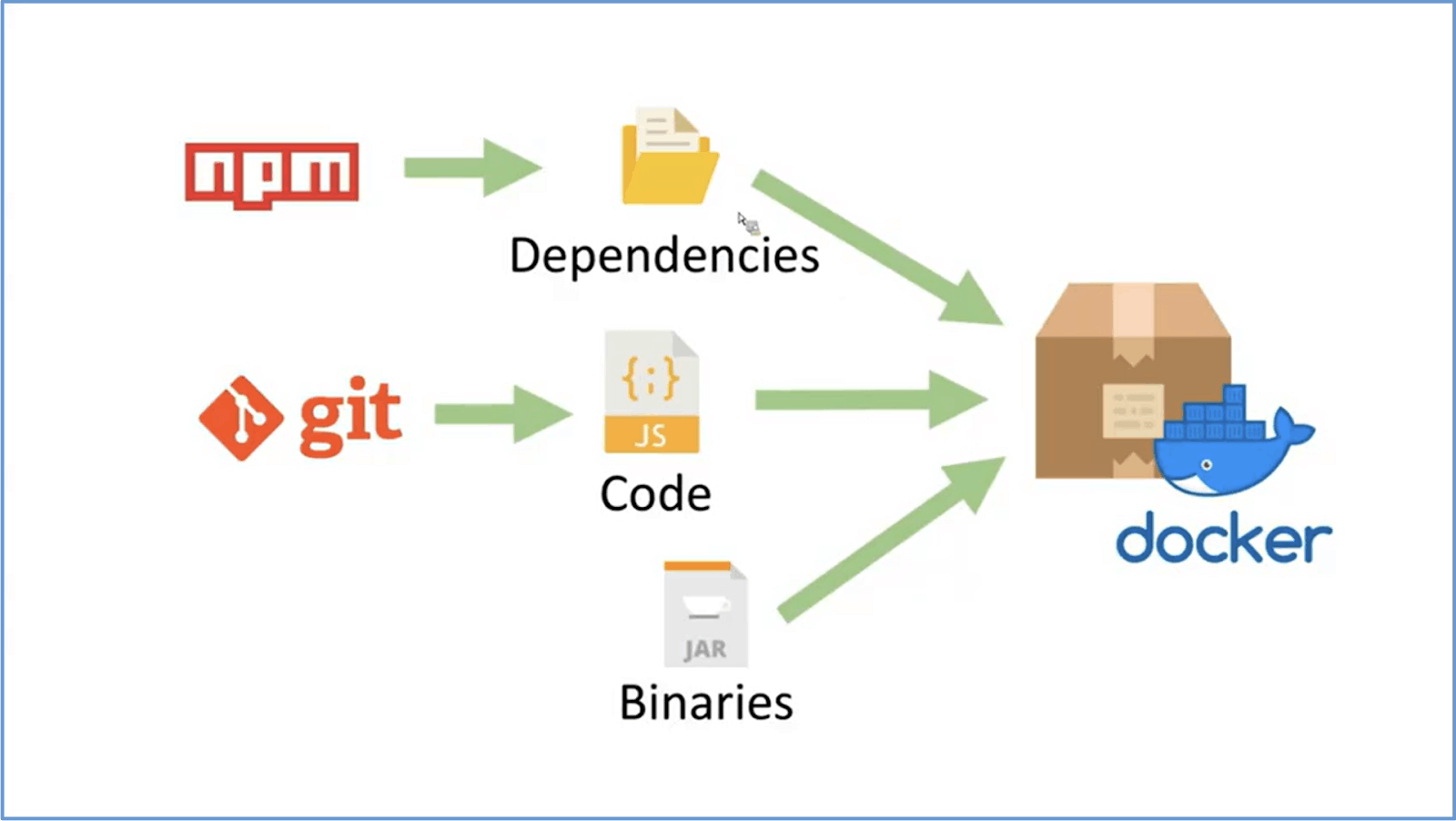
If you look at the below image, you can see that all the dependencies, code, and binaries should be mentioned in the docker file.
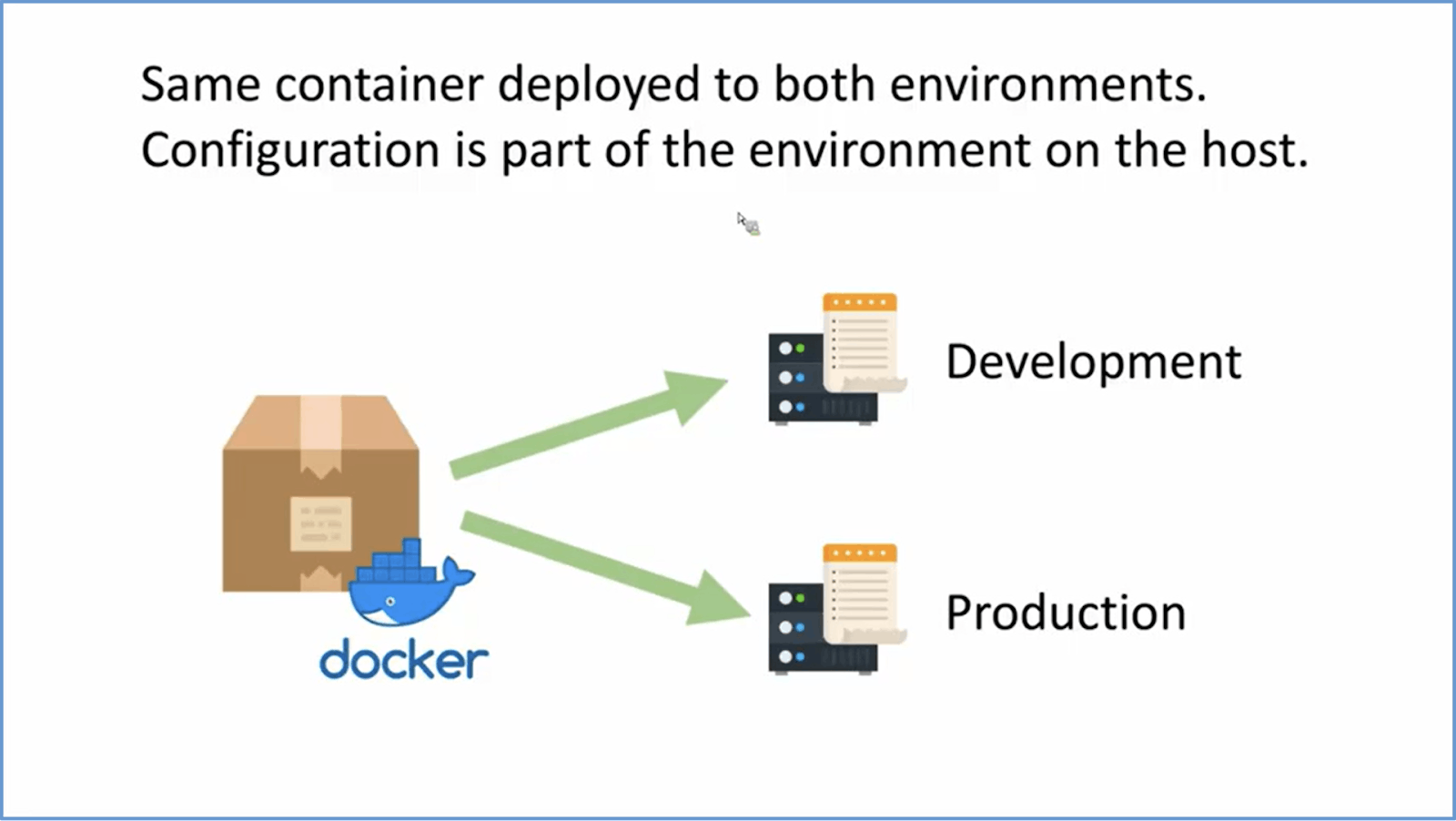
#Configuration
While dependencies should be part of the code, the configuration should be part of the environment as it will vary from one environment to another. It must be strictly separate from the code. So the code will remain the same across all the different environments, but the configuration for a deployment will be specified through environment variables in its own environment. These environment variables are read by the code on the runtime. Because the environment configuration is not part of the code, that’s why the .env files are in the git ignore. One example of such configuration is a different URL of the S3 bucket for staging and production.
Although the docker file can read from .env files, which is acceptable for the local development environment; however, on the cloud, you would want to use something like AWS Systems Manager to save all the environment-specific configuration securely.
For containerized apps, the same container should be deployed to different environments. At runtime, the container will retrieve the configuration from the environment (through .env file, AWS SSM, etc.) If you use AWS ECS for containerization, you can mention environment variables using task definition in the ECS.
#Backing services
According to the Twelve-factor guidelines, a backing service is “any service the app consumes over the network as part of its normal operation.” It can be an internal service or an external integration. Whether internal or external, every backing service should be treated as an attached resource. In fact, the local services should be like remote 3rd party services. That means your application should be aware of it but must not be dependent on it. In other words, the service usage should be so that there is a loose coupling between this attached resource and the application. Standard backing services include AWS Lambda, S3 buckets, a 3rd party API, RDS, etc. Ideally, these services should be available to your application in the form of configuration.
In most cases, these services should be accessed through a URL and/or credentials, etc. That way, if the location or connection details of any services are changed, you do not need to change your code; only the configuration should be updated. See the below image for illustration.
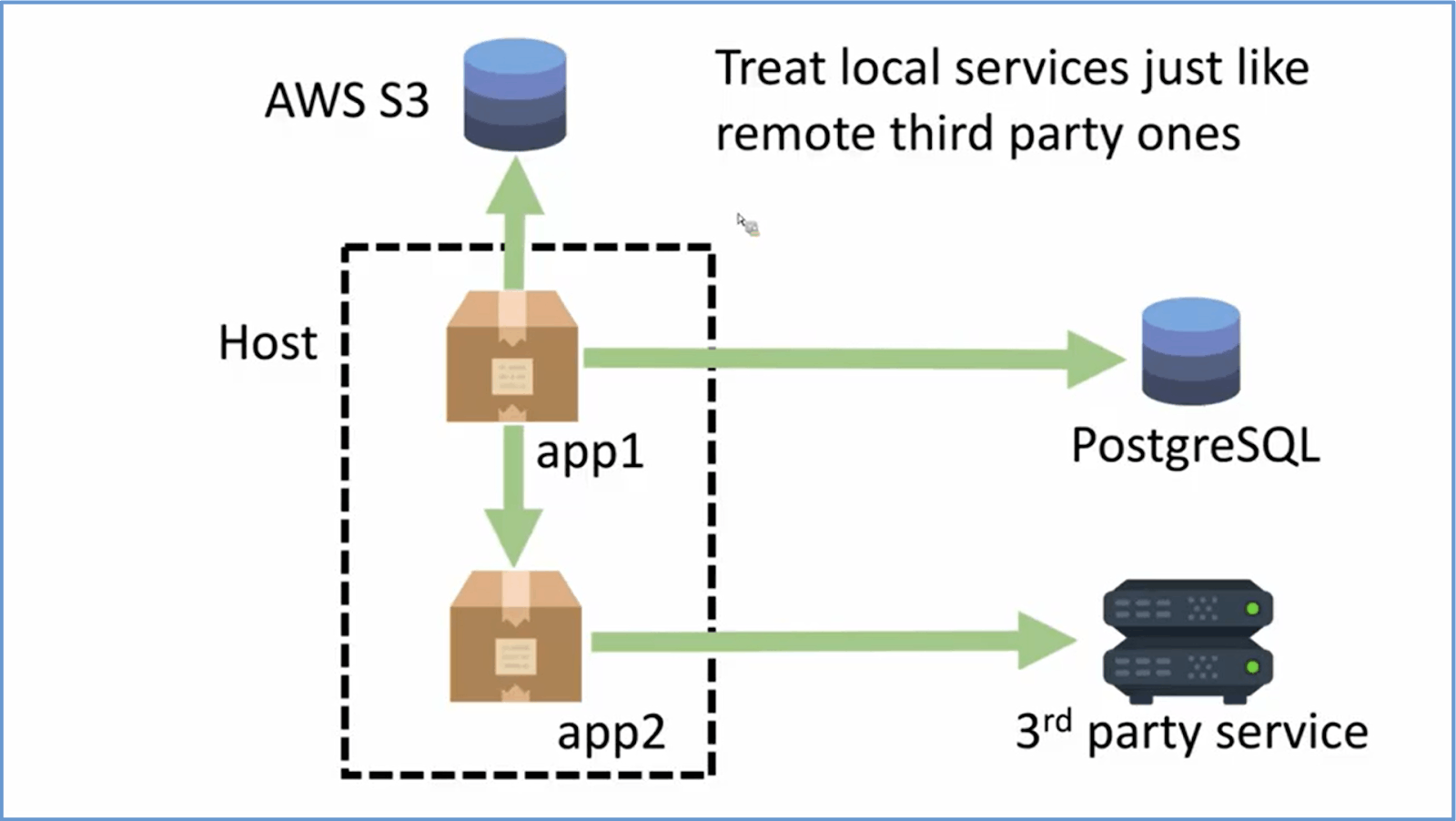
One example in the case of Amazon DynamoDB is to make the name of dynamodb part of the configuration instead of hard-coded in the code. That way, the application is not dependent on the dynamodb service.
#Build, Release and Run
Note that Build, Release, and Run are three different stages and should be independent of each other. None of these should be tightly coupled to another one. Here is what happens in each stage:
BUILD – Package the application code as a Docker image. You can use AWS codeBuild or anything similar to that. The result is, that the container image is pushed to some image repository like AWS ECR.
RELEASE – The pipeline combines the build artifact (docker image) with environment variables to form a release.
RUN – If you use Amazon Elastic Container Registry (Amazon ECR) for containerized applications, the task definition will describe how to run the docker container. The container image URL is also mentioned in the task definition. This is all the information that ECS needs to run the application in the provided environment. In most cases, the pipeline will deploy the application using ECS. See the below image for reference.
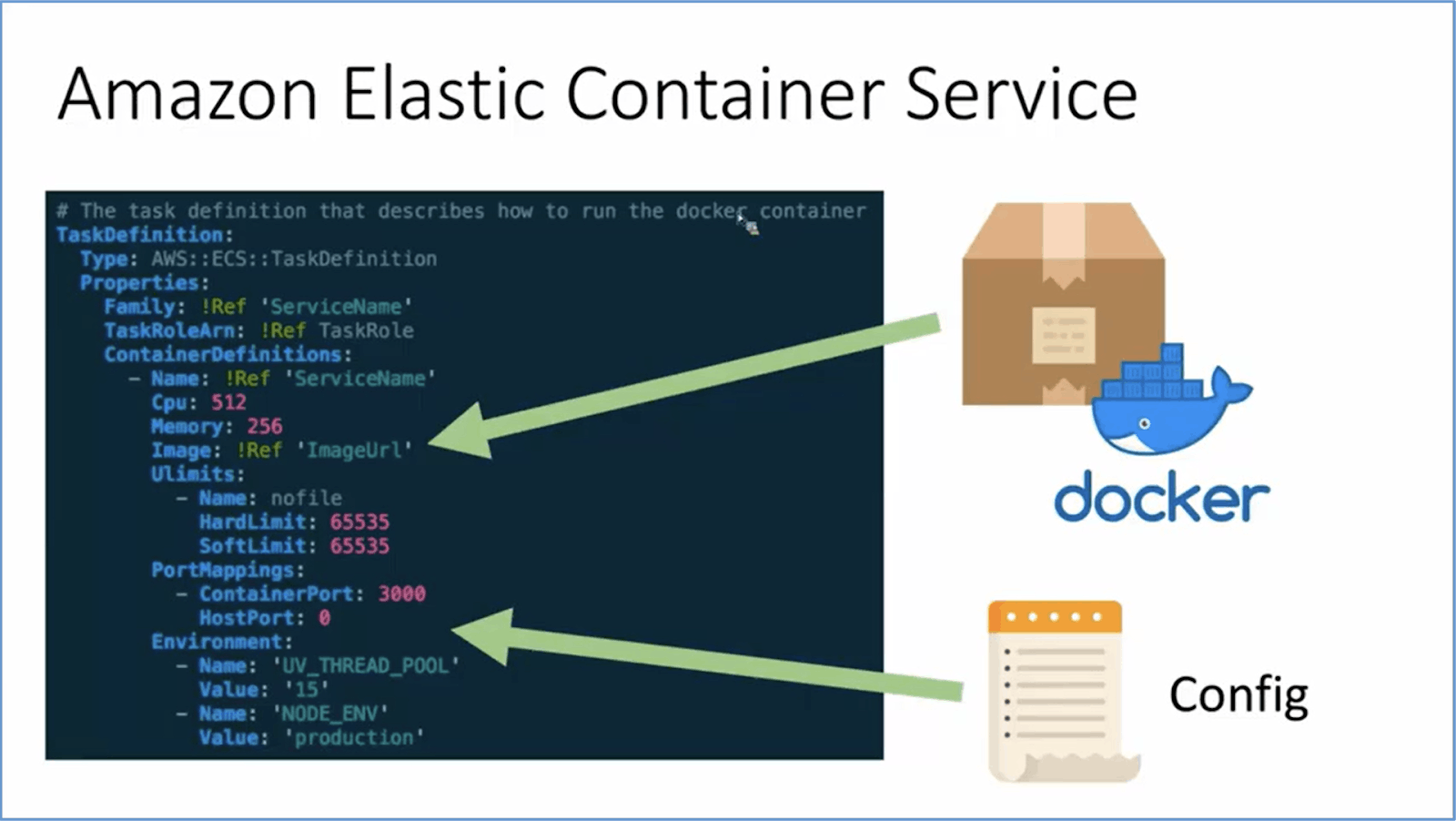
It is suggested that container images should be created for every code push and treated as deployment artifacts.
#Stateless Processes
The Twelve-factor guidelines state that the application should be built as a collection of processes that are stateless. That means containers will be stateless and immutable. Any state must be persisted in a portable external service like a database or cache etc. The processes will not share anything with each other. Nothing should be stored on a local disk or local memory. Note that Amazon Elastic Block Store (EBS) is network-based mountable storage, not a local disk.
See the below image, which describes this solution.
Saving any state or data to your host or EC2 will be a hindrance in scaling as well. You cannot use autoscaling because removing any underused instance will permanently lose its data. Similarly, a newly added host can easily reference data if it is stored in an external service. This improves stability and scalability as well.
Ideally, it should be one application process per container. For a simple web-based application, you can have one container for your API’s/backend and one container for your front end.
#What's Next?
This was part one of the article where we discussed some of the best practices for implementing containerized microservices using the Twelve-factor methodology, including the areas around the codebase, configuration, code packaging, code builds, and stateless processes. Continue Reading: Implementing Microservices on AWS with the Twelve-factor App – Part 2
Your Favorite DevOps Automation Platform
Qovery is a DevOps Automation Platform Helping 200+ Organizations To Ship Faster and Eliminate DevOps Hiring Needs,
Try it out now!
Your Favorite DevOps Automation Platform
Qovery is a DevOps Automation Platform Helping 200+ Organizations To Ship Faster and Eliminate DevOps Hiring Needs,
Try it out now!.jpg?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max)

.jpg?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max)